
货柜项目总结
【打招呼】hr您好!我叫廖乾能,全日制统招本科,有3年的java开发工作经验,精通MySql的底层结构、存储引擎、事务隔离级别、锁、索引、MVCC工作原理,熟悉sql优化工作;熟练使用 SpringBoot、 SpringCloud 微服务开源框架, 熟悉 SpringAOP、 IOC 设计思想;深入理解垃圾回收算法及回收机制,有过实际调优经验;熟悉 Redis 持久化机制,过期策略以及集群部署,熟悉RocketMq事务消息底层原理,掌握消息丢失、消息重复、消息幂等问题的解决方案。期望能够有机会加入贵公司。
AW4WQ07A7BAPFN4J
【面试】面试官您好,我叫XXX,有个两年的java开发经验,掌握的技术栈有SpringBoot、SpringCloud;数据库的话MySQL,中间件Redis、MQ都了解其原理;最近在做的项目是智能货柜,该项目主要部署在商圈、小区,用户通过扫码-开门-获取商品-关门的自助式购买,我在项目中主要负责设备服务,订单服务,其他的服务也有一定的了解,请问面试官您有什么想问的吗?
设备服务:存储设备的信息,设备通过MQ与其他服务进行通信
订单服务:扣款结单
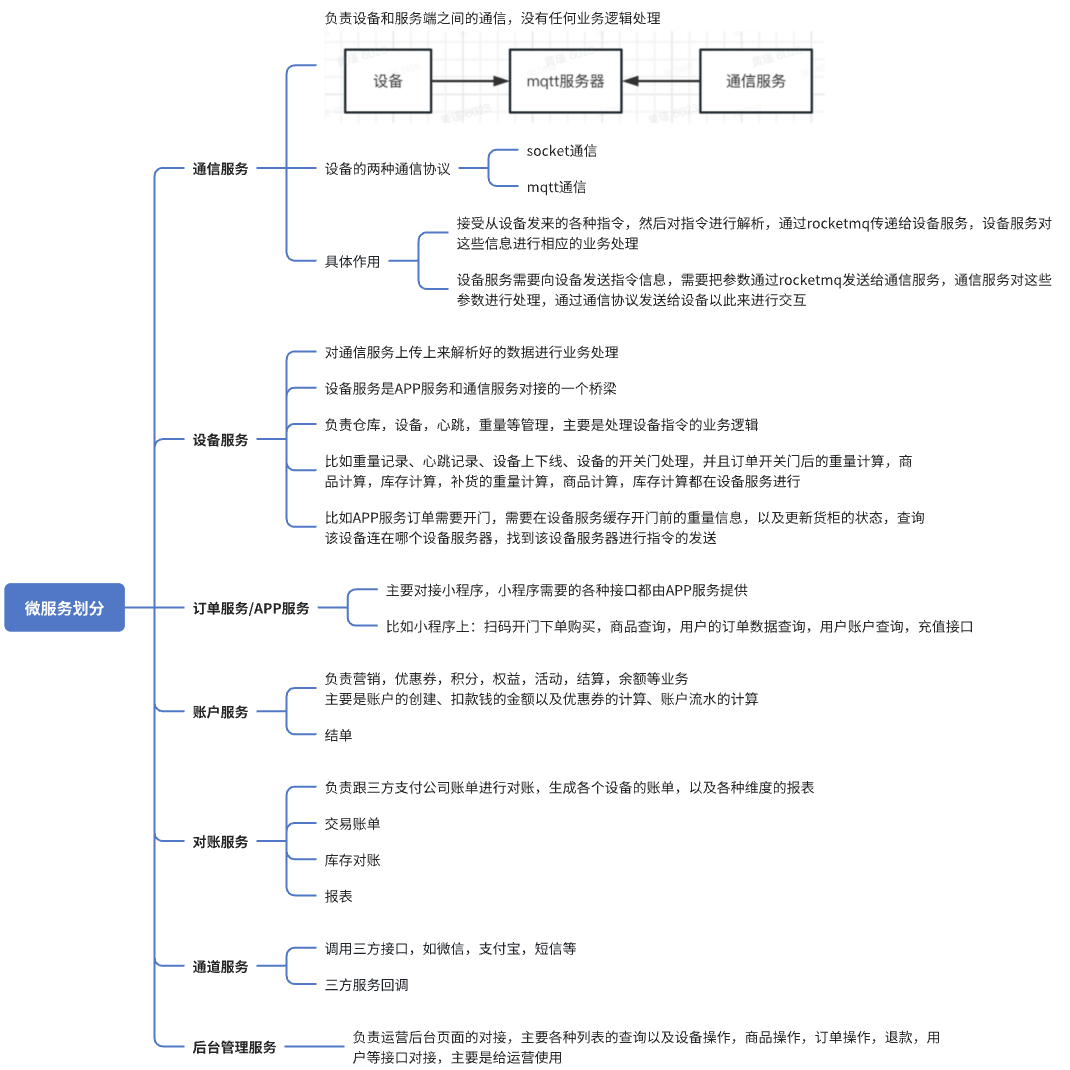
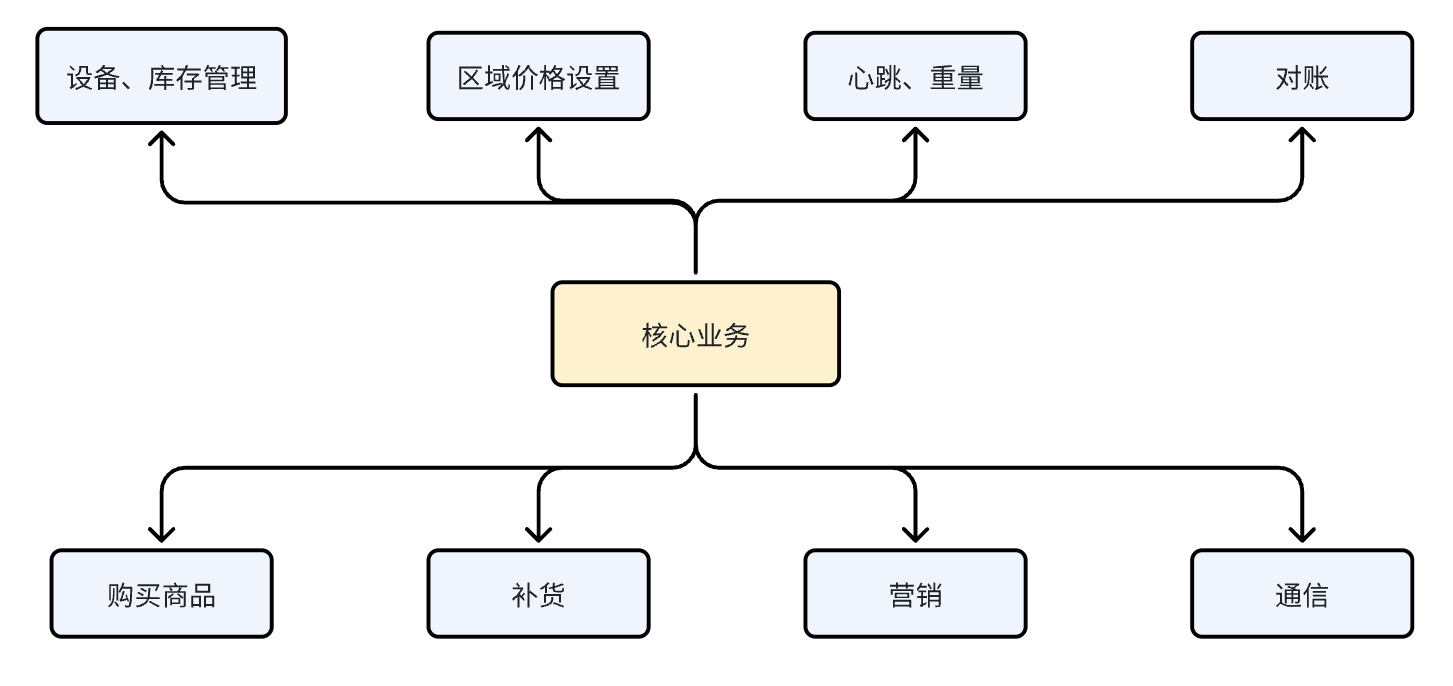
微服务划分:通信服务、设备服务、订单服务、账户服务、通道服务
一、参与设计
介绍:我之前做的是一个智能货柜的项目,部署在在商场、小区等场所。该货柜使用的流程是,用户通过扫码确认免密支付后,货柜打开,用户拿完东西后关闭货柜,自动扣减钱
Leader和运维搭建了一个可视化平台,用于检测堆内存,以及内存泄漏的情况
RocketMQ、Redis、MySQL使用的是阿里云的产品
回答问题先从业务整体来说,问到细节再说细节,没问到也好
有几个端?作用是什么?
- 运营管理后台:运营管理后台是给我们运营公司的管理人员用的,主要作用有基础数据的管理和统计分析功能。
- 供应商后台:供合作商使用。主要作用是合作商查看自己点位的分成【某个摆放货柜的地点(学校/小区/写字楼/门店)卖出去的订单,赚到的钱要按约定比例分给合作方】
- 运营移动端:供运营企业的运维和运营人员使用。主要作用是处理工单业务,比如说补货、售后处理。
- 用户小程序端:供C端用户使用。消费者扫描售货机上的二维码可以打开此端,我们研发负责小程序前端和后端接口一起配合完成整个购物流程。
- 设备端:没有界面。安装在每个售货机中,主要作用是接收服务端发来的出货请求,调用硬件完成出货。
系统一共分为哪几个库?有没有做分库分表?大概多少张表?
所有业务数据都在同一个 MySQL 库中,没有做分库分表,我们采用的是TIDB的方式,主库+历史库。
核心的表大概有30多张。
你有没有参与过表设计?如何进行表设计?
设计数据库表,我的经验就是先从产品原型中提炼出表名称,比如产品原型中,有一些基础数据的维护,那么这些大概率都是一些基本表。这类的表设计相对比较简单,就是从产品原型中提取输入和输出项,此外,我还会加上逻辑删除字段、状态字段、创建日期和更新日期这样的字段。 另外还有一些经验,虽然理论上我们要遵循三大范式,但是实际上是要有变通的,比如空间换时间。
项目有多少个接口,多少个页面?
【没有固定答案,合理即可】
项目接口大概有80多个接口。页面总共大概40个页面左右。
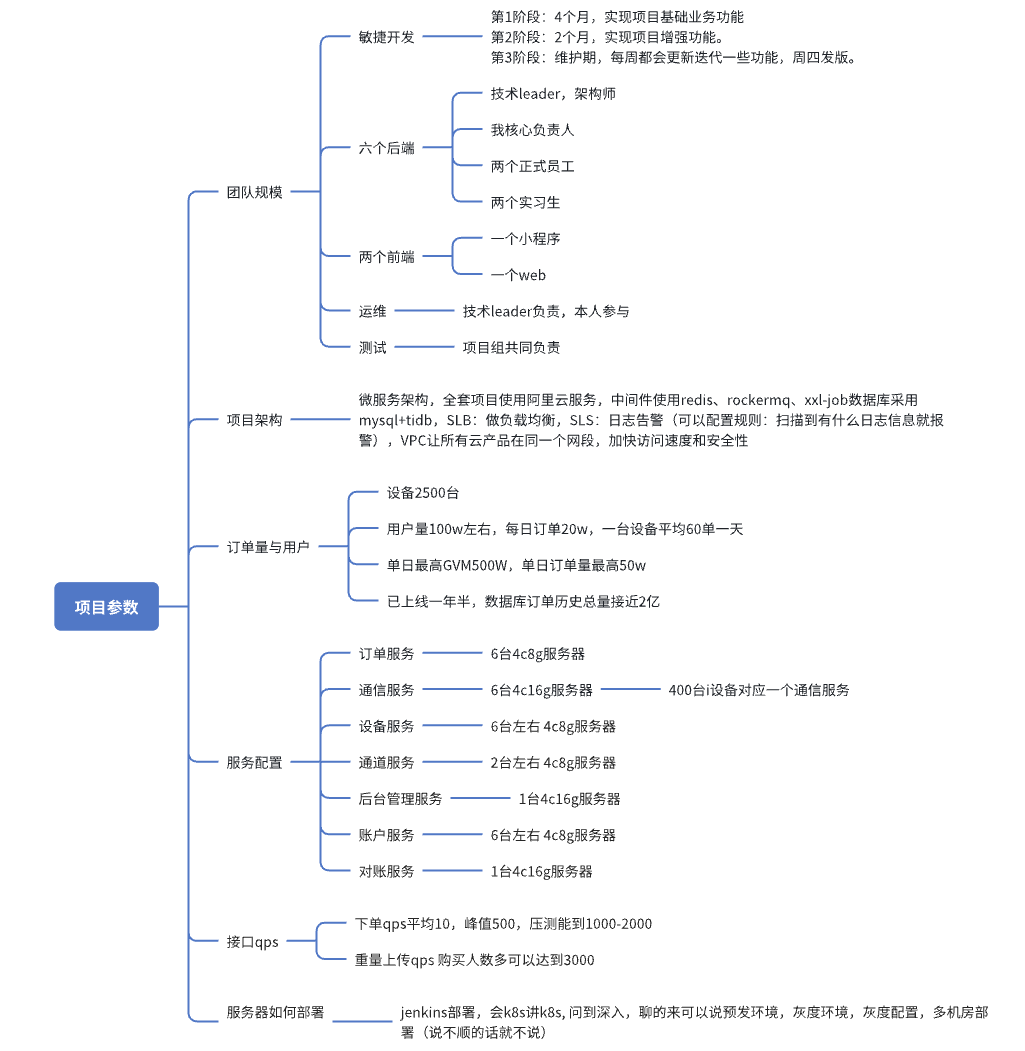
你们项目组有多少人?人员构成是什么? 开发周期怎么定?
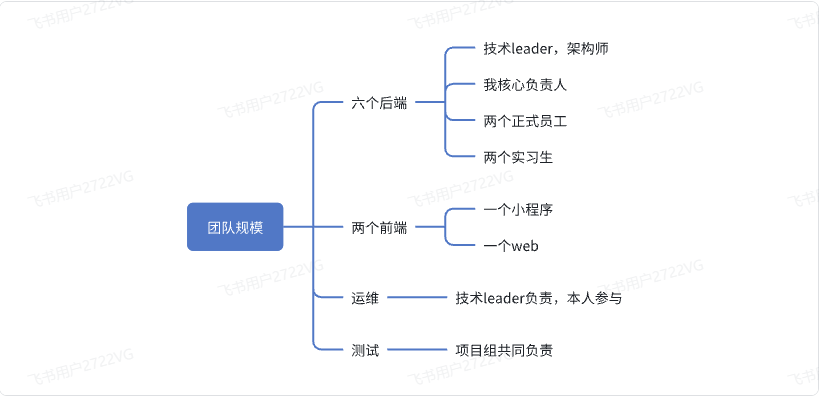
我们项目采用敏捷开发,分三个阶段:
- 第1阶段:4个月,实现项目基础业务功能
- 第2阶段:2个月,实现项目增强功能。
- 第3阶段:维护期,每周都会更新迭代一些功能,周四发版。
你们项目的开发流程是什么?
项目采用前后端分离的模式开发。
项目启动后,由产品经理用了大概一周时间设计了第一版的产品原型,召开两次需求评审会来确定最终的需求。
接下来设计组开始进行效果图设计,开发组进行技术研讨会确定技术选型,并确定接口文档,与前端人员确认。
接口确认好,前端就按照效果图、接口文档进行前端代码的开发,而后端就按照产品原型、接口文档进行后端代码的开发
前后端开发完成后,前端和后端进行前后端联调。
最后测试、上线部署。
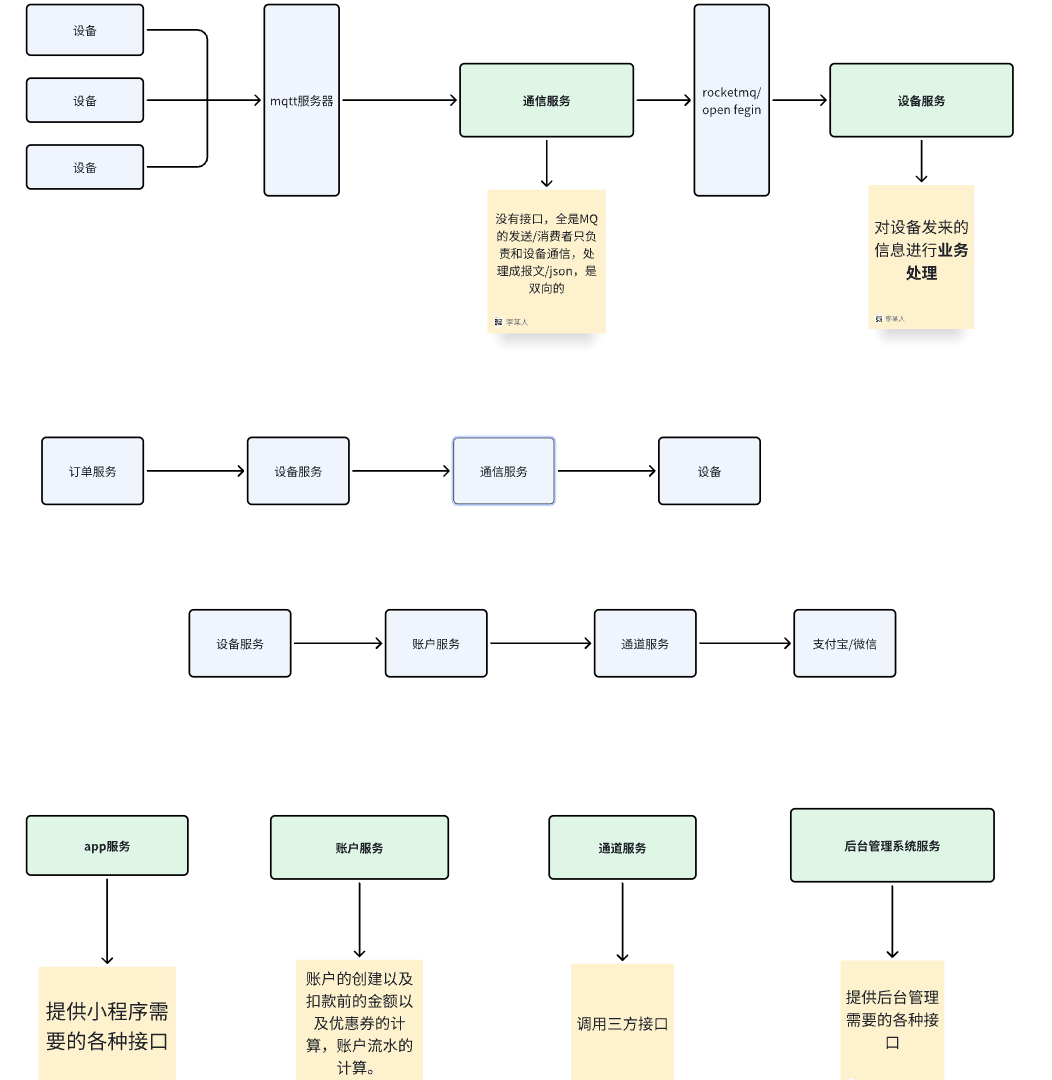
微服务之间通信
- 正常服务之间就是用的 fegin
- 异步的操作就是用 mq
- 设备订单计算好商品,mq 通知账户服务结算订单,还要通知补货
负载
外部:nginx,外部请求进来以后,打到哪台入口机器
内部:Feign 负责发请求,具体选哪个实例由 LoadBalancer(旧的是 Ribbon)决定。
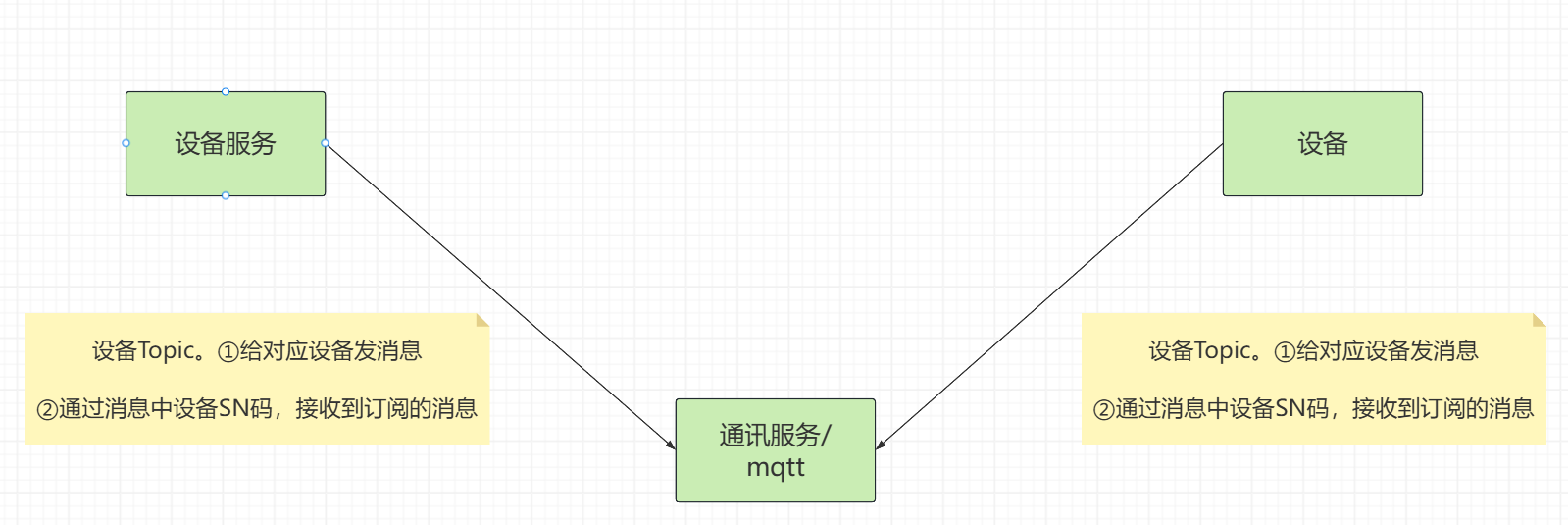
设备服务与设备之间的通讯
我们使用的是mqtt,用的是阿里巴巴的封装好的sdk
项目中有哪些难点、挑战
设备难点:
难点:设备的命令的不确定性;设备的不稳定性。比如 不发开门指令open,不发关门指令close,心跳的自我保护机制。
难点:设备的一些网络状态、命令的不稳定性。
因为我们是做软件开发的,公司还会有采购,他们不会和我们沟通要采购那家公司的设备,所以我们开发的过程中很无语的,有的设备坏了,有的设备数据上传不了,有的设备好好的突然坏了,莫名其妙。还有就是前后端联调也是有很大的困难的。
前端后联调:
当接口测试没有问题后,需要进行前后端联调。前后端联调中如果遇到问题,首先根据http状态码判断无法联调成功的原因,404表示地址不对,500表示后端报错。如果404就要检查是前端和后端,哪一个没有按照接口文档编写地址导致无法对接成功。如果500,就要查看后端控制台的报错信息,根据异常信息找到报错的语句。这种情况大多数是因为参数传递不正确。
根据上述方式,基本可以断定是前端的问题还是后端的问题。如果是后端的问题,根据报错信息无法找到原因的,可以再尝试在关键代码上打上断点,逐条运行,观察变量的内容是否和预期结果一致。
二、核心流程梳理
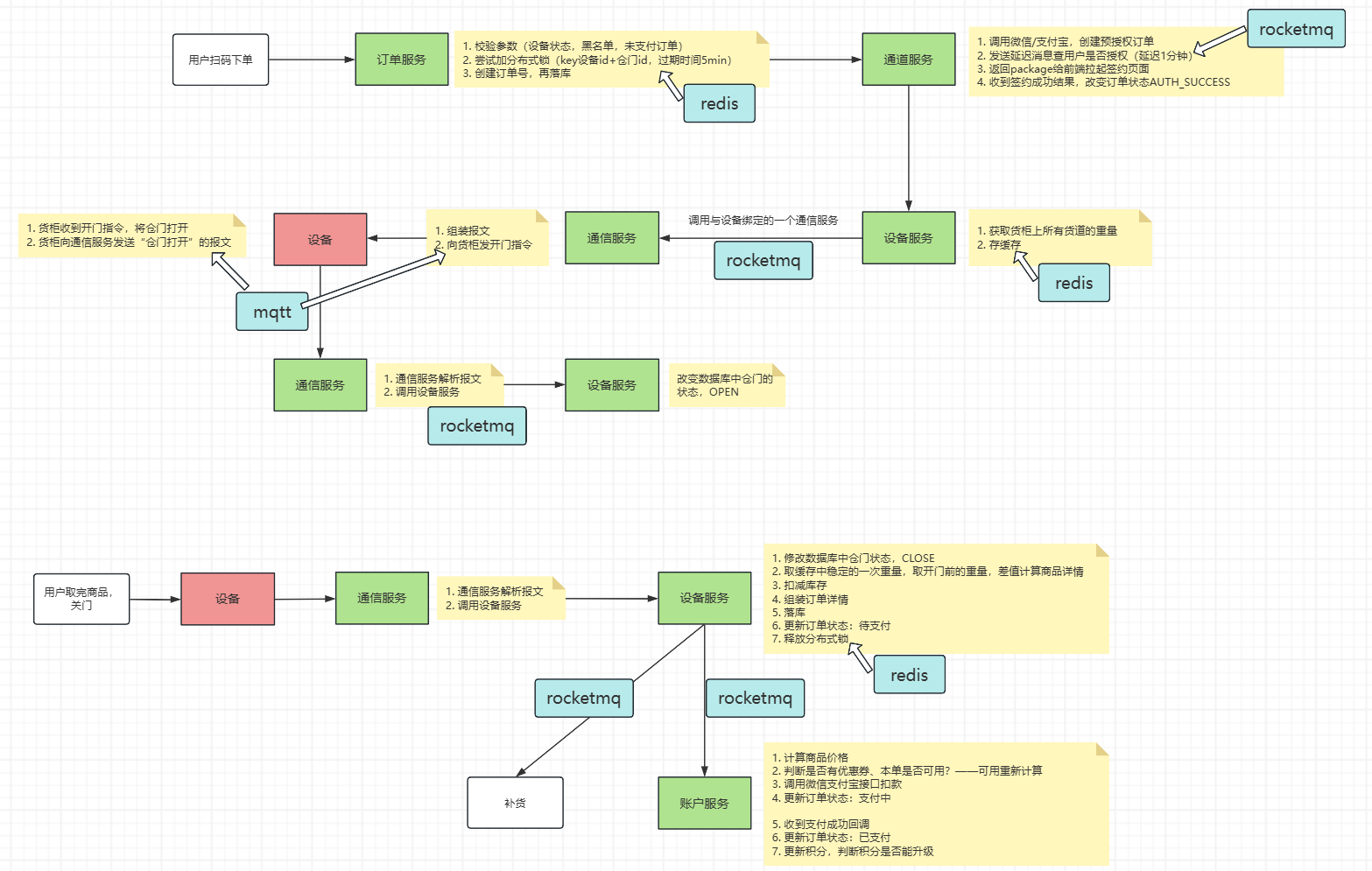
具体购买流程

用户扫码,后端会对参数进行校验,判断用户是不是在黑名单中;校验成功后,通过加分布式锁将订单落库,再请求到支付宝/微信做一个预约下单,授权预约下单后会给前端发送一个签约的package包,用户同意后,我们会收到支付宝/微信的回调,之后会调用设备服务开门,在开门之前会记录所有货仓的重量,用户卖完东西后,再次记录所有货仓的重量,用这两个做差值得出用户买了什么商品;通过MQ发送消息调用账户服务结算,释放掉分布式锁,在账户服务中会涉及到优惠券、积分、余额的处理,同时这个消息会发送给一个触发补货的服务,这个服务会去查看设备是否需要补货,如果需要,通知调度人员去补货
更具体地流程

数据库表

设备上线

设备服务收到设备登陆服务器的请求,会查看是否有该设备:
- 如果有该设备:修改设备表的设备状态为在线,更新设备缓存状态,更新设备服务中设备通信信息,更新通信服务中设备、Channel信息
- 如果没有该设备:添加该设备,修改设备表的设备状态为初始化,添加设备缓存
设备的管理,设备的维护
-
设备有仓门,仓门有货道,如果是重量柜,每个货道卖一样的商品
-
每个设备都有对应的仓库,每个仓库有负责的补货人员
-
每个仓库有各自仓库的库存管理,设备每个货道可以配置补货阈值,低于阈值触发补货调度任务
心跳/下线流程
最开始的设计是
- 设备每30s向通讯服务发送心跳报文,通讯服务解析后向Redis存入一条消息,key:sn码,value:null,过期时间设置为60s(防止死锁)
- 在设备服务中开一个定时扫描任务,如果key过期了,就判断设备下线
但这存在一个问题:设备可能因为网络波动频繁下线
于是我们又引入了心跳保护机制,为了避免因为网络波动问题,导致的大面积设备下线,造成误判
- 设备每30s向通讯服务发送报文,里面包括了心跳时间,重量等设备信息,通讯服务解析后向Redis存入一条心跳消息①
{设备sn码:heartbeat,当前时间戳} - 在设备服务开一个定时任务,通过redis命令
zrangebyscore查找①超过60s并且没有心跳的设备,如果有这样的设备,就会判断是否满足心跳保护机制,决定设备是否下线 - 心跳保护机制:我们的设备有2500台左右,一分钟正常能收到5000次心跳,我们设置了一个阈值80%,如果一分钟收到的心跳总数小于5000 * 80% = 4000 次,就会认为是服务器故障,不会让设备下线,通知运维人员检查;
- 记录一分钟心跳总数,我们按分钟分桶:key 里带分钟时间(比如 ②
{heartbeat:cnt:时间,数量})。心跳到达通讯服务时INCR该 key,设备服务定时任务每分钟GET上一分钟 key 的值即可,并设置过期避免堆积。 - 如果不满足心跳保护机制,将该服务下线,更新数据库设备的状态,更新缓存状态
②
{heartbeat:cnt:时间,数量}里面的数据可能:{heartbeat:cnt:202512241106,4800}、{heartbeat:cnt:202512241107,4500}Redis 的
INCR key有个特性:
- 如果
key不存在,Redis 会把它当成0,然后执行+1,结果变成1- 所以下一分钟的 key 不需要提前创建,**第一条心跳到来时就自然创建了
重量
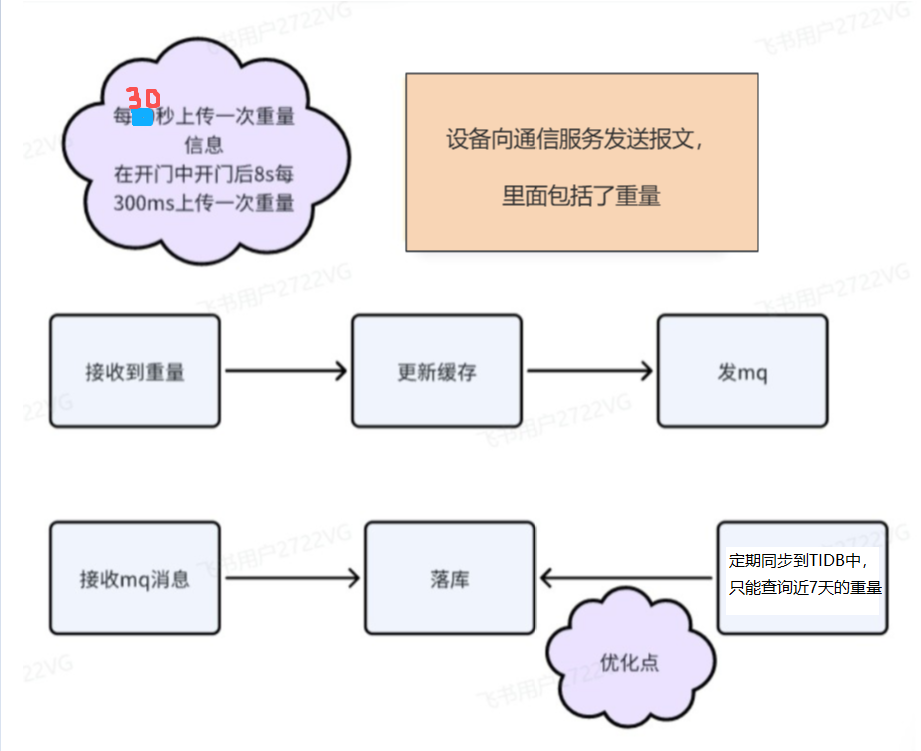
- 仓门没有打开之前是每30s上传一次重量信息,在仓门打开5s之后,每300ms上传一次重量
- 设备向通讯服务发送报文,里面包括了心跳时间,重量等设备信息
- 服务器接收到数据后,更新缓存,发送MQ,目的是进行削峰,通过MQ再落库
- 我们还有一个服务式定期同步7天内的数据放入TIDB中
使用重量柜产生的问题
🚀因为选择了重量柜这种性价比的柜子,有些问题是无法解决的
✅同一个货道,用户拿走,又丢一个相同重量的东西,不扣款
- 当用户拿走一个商品,检测到重量的减少会记录扣款,我们的货柜是每300ms记录一次重量,很容易检测到。
- 对于丢了一个相同重量的东西,由于钱已经扣除了,因此不会造成我们的损耗
✅同一个货道,用户拿走,又丢一个更加重的东西
- 当用户拿走一个商品,检测到重量的减少会记录扣款,我们的货柜是每300ms记录一次重量,很容易检测到,因为支付宝/微信一旦结单后就不能够进行扣款操作了。
- 当用户丢了一个更加重的东西时,货道也会有一个重量检测,告警处理,订单设置异常
- 最终,用户会因为拿了一个商品而扣钱
✅用户从货道 1 拿出东西,不想买了又放到货道 2 里了
-
货柜上贴有标志:请不要随意打乱货柜内商品的货道
-
货道 1 的重量还是会降低,货道 2 的重量会变高,我们货道也会有一个重量检测,比如货道 2 重量增加的很多,会给货道 2 标记可能异常告警,通知人员去排查
-
用户关门,还是会扣货道 1 减少的商品,该扣还是扣,用户发现扣钱后会投诉联系客服,管理人员会进行排查,通过每个货道的摄像头,看描述是否一样,货道 1 是否重量减少,货道 2 重量是否增加,没有问题进行退款
怎么计算用户买了什么商品?
我们是通过记录开门前后的重量对比计算,通过误差阈值控制,如果超过了阈值,客户联系才进行退款,如果在阈值之内,就认为是是资损
货柜已开门但是设备下线了怎么办?
首先开门前还会检验一下设备状态,此时下线后直接将该订单改为异常
如果开门后设备下线,不会影响结单,只是将设备的状态改为了下线,但是还是可以发送关门指令的
如果设备开门了并且发送不了关门消息,订单也会设置为异常,可以人工结单
设备补货、调度流程

- 每一次设备服务向MQ发送消息结单,对商品的库存扣减的同时,会触发货道是否需要补货
- 如果达到补货的阈值,会通过飞书通知补货人员前去补货
- 补货人员先检查设备状态,再通过h5页面扫描二维码调用补货的接口,加分布式锁,创建补货订单并落库,设备服务调用开门,缓存开关门的重量来判断商品数量,增加库存,更新补货订单状态
对账流程

外部对账:
【说】支付宝次日9-10点和微信次日10点会给我们 结算账单 + 交易账单,结算账单是对“钱”,交易账单是对“订单”,交易账单我们会从 OSS 流式读取,按 5000 条一批做分片对账。
【了解】结算账单的一个excel表格,结算账单会告诉我们昨天结了多少钱,什么时候到账,到账到哪里,那个支付公司都会给我们。
【了解】交易账单的excel表格,需要我们每一笔都去对,主要是对交易订单和系统订单的订单状态,看支付公司和我们数据库记录的状态是否一致;对订单金额;对他收取的手续费是否一致
内部对账:
每天晚上0点看一次重量,算出库存量,加上白天的补货计算出【库存的减少量】与【订单的商品数】是否一致,如果不对,会调取监控、查看一些重量变更记录
生成报表流程
报表就是账单
- 通过
线程池 + CountDownLatch,生成不同维度的报表,每个线程处理一个维度,等每一个线程都处理完,再进行汇总,处理接下来的任务
不同的维度
- 以商品数据
- 以地区统计数据
- 不同时间的数据
1 | ExecutorService pool = Executors.newFixedThreadPool(3); |
营销体系

- 优惠券分类
- 优惠券大概分为三种,满减券、现金券、团购券;满减券就是达到多少金额就可以减一部分钱;现金券就是无门槛卷;团购券是购买指定商品不需要钱
- 优惠券的获取方式
- 我们可以通过活动,秒杀、新人用户、拉新人的方式获取优惠券
- 优惠券的使用规则
- 优惠券的使用规则可以简单配置,比如团购券可以一次性多使用几张,而现金券、满减券的配置规则只能一次使用一张
优惠券秒杀
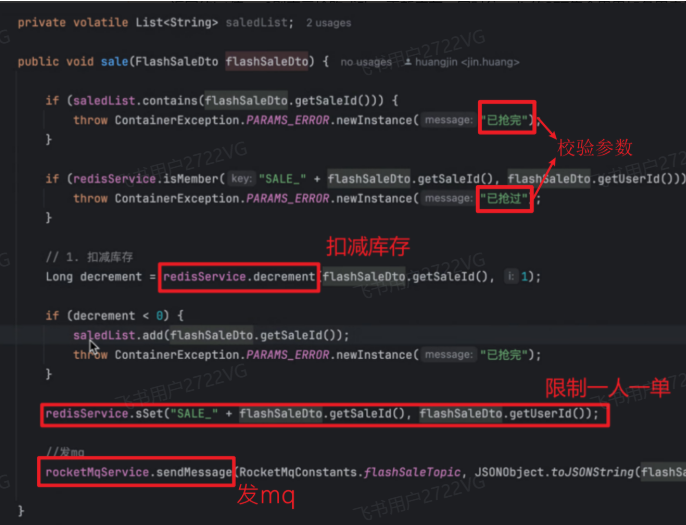
优惠券的秒杀功能主要使用Redis减少数据库的压力,mq异步消峰处理落库
在秒杀之前,向Redis中加一个set结构的数据做缓存预热,key就是秒杀券id,value就是库存量
前端会采用滑动验证防止用户连续点击,后端我们自定义了一个全平台注解,它的作用是针对同一IP800毫秒只能请求一次,后续请求全部拦截。对于库存的扣减,我们采用Redis的decrement命令,返回值如果 $\ge 0$表示抢购成功,同时往Redis的Set集合中加一条用户抢到的记录,限制一人一单,发送mq进行后续业务操作。
充值流程

退款流程
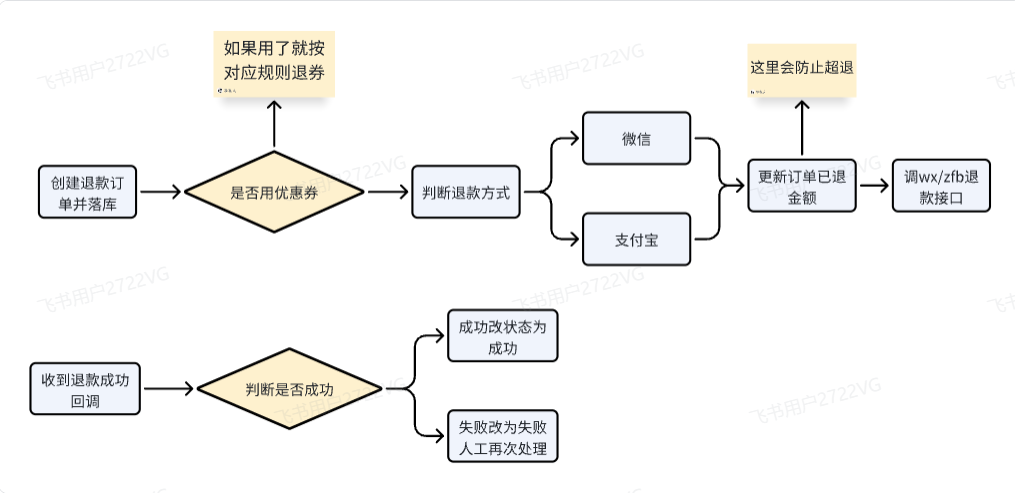
一般退款都是因为商品质量问题,或者说拿了别人放错货架的商品,导致扣款扣多了,系统仅支持七天内退款(数据库只会存七天内的重量信息),退款需要客户联系客服,我们后台进行退款
- 解决超退
- 一个订单多次退款会有限制:where 条件 已退金额 + 本次退金额 $<$ 支付金额
- 退优惠券
- 我们采用的是先退优惠券再退钱
- 退积分
- 我们会按照比例扣除积分,如果积分已经被用户使用了,那就只能算给用户的补偿,因为大多数退款都是因为商品的问题
扫码登陆流程
小程序如何获取用户唯一标识(openid)?
前端组装appid调用微信接口得到jscode,把jscode给后端,后端用jscode请求wx可以得到用户的唯一标识(openid)
支付宝文档

微信文档

支付宝、微信支付回调的幂等性是什么做的?

✅如果支付宝连续回调两次怎么办?
做接口幂等
-
就是分布式锁,避免两条东西同时修改
-
MySQL 的行锁,唯一索引保证唯一
-
通过乐观锁,update ··· where 支付状态 State = 支付中,通过这种一个更新成功,一个更新失败
✅如果两次结果不同怎么办?第一次支付失败,第二次支付成功
- 这种都会做告警处理
- 然后我们都会再查支付状态,微信支付宝都会提供订单查询的接口,查询一下到底是怎么回事
支付宝和微信 有啥区别?
最大的区别:
-
支付金额的单位不同
-
微信的单位是 分 (且数额≥0)
-
支付宝的单位是 元 (数额≥0.01)
-
-
微信需要知道支付详情,支付宝不需要知道。
-
支付宝下单只能有1次,比如支付宝有未支付的一笔订单那么就不会开启下一次订单
- 微信则有3次
-
支付宝退款是同步接口,微信退款是异步接口
区域价格设置
分散剂来存储商品价格
- 货柜价格表(一级):货柜sn码——货道id——商品id——价格
- 区域价格表(二级):区域——商品id——价格
- 商品价格表(三级):商品——价格
查询价格时,先从一级价格表查询,如果没有该商品的价格的话再去二级商品区间表查询,如果还没有的话,就去查询三级价格表(三级价格表式一定有的)
通讯服务宕机怎么解决?
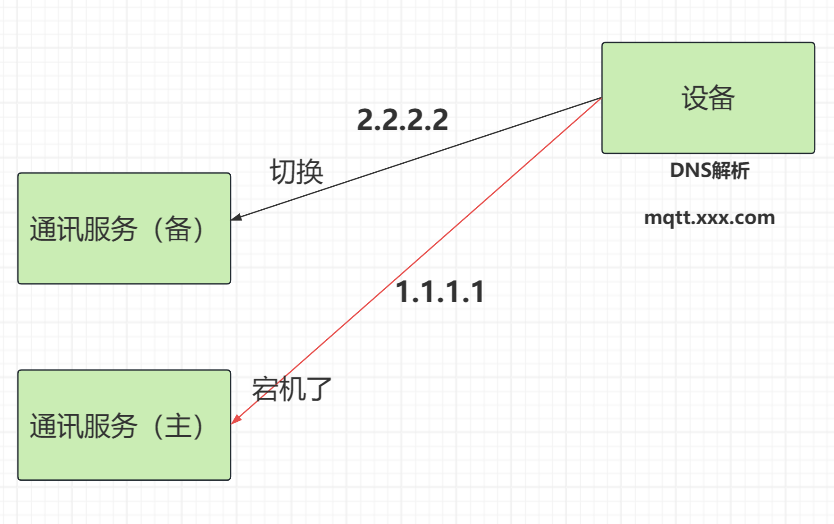
【设备——>通讯服务】
我们给通讯服务配置了一个固定的入口:mqtt.xxx.com,这个域名的DNS会被设备解析为某个通讯服务的IP(主服务器)比如mqtt.xxx.com——>1.1.1.1
设备通过这个域名去访问通讯服务,实际连的是解析域名得到 IP -> TCP 连接 -> 建立会话
如果主通信服务挂了,设备会尽快/在 TTL 窗口内把这个域名切到另一个备用通讯服务上
这就是域名切换(DNS 切换):
- 原来:
mqtt.xxx.com -> 1.1.1.1(主) - 故障后:
mqtt.xxx.com -> 2.2.2.2(备)
【设备服务——>通讯服务】
设备服务:通常是调用一个服务名(比如 comm-service)→Feign 负责发请求,具体选哪个实例由 LoadBalancer(旧的是 Ribbon)决定
有用到RocketMQ吗/为什么要使用RocketMQ?
我们的项目是一个分布式项目,而RocketMQ支持分布式事务消息,分布式消息事务是通过 半消息 + 本地事务 + 事务回查 来实现的
-
通信服务 通过 消息队列 和其他外部服务进行信息交互,没有接口的提供,只有接收消息、发送消息跟其他服务进行交互
-
关门 设备服务 收到商品详情的时候,通过消息队列发送给账户服务去结单,另外一个发送给设备服务的补货 通知它补货
-
所有发短信,就是发送短信通知运营人员校准或者补货,发短信通过通道服务的消息队列去发送短信
-
所有延时任务:签约查询、查询开门等
有用到Redis吗?
缓存设备信息:货柜——>通讯服务mqtt——>设备服务,在设备服务这里进行Redis缓存(Redis中key是device_id(设备id),value是一个大对象序列化成JSON(设备sn唯一编码,商品信息,仓门信息,state,重量、last_heart_time、通道服务id))
分布式锁:开仓门下单的时候,利用Redis做分布式锁。同时补货、换品、改价也用的是这同一把锁
商品库存数量:我们会把库存信息放 Redis 作为缓存,用于高频查询和补货判断;但最终库存以数据库为准
有用到分布式事务吗?
下单时订单库、账户库都有写操作,我们用 Seata AT 做分布式事务:一阶段各分支本地提交并写 undo_log,二阶段统一提交/需要时用 undo_log 回滚。
为什么用 Seata AT 模式?
技术选型的时候考虑到它是阿里的产品,同时侵入小:基本不改业务代码,入口加
@GlobalTransactional;AT模式下的最终一致性也符合我们的需求。吞吐量高
分布式锁
我们在下单的时候会用到分布式锁,因为我们要保证同一时间一台设备只能有同一个人购买,所以这里使用了分布式锁
使用了 Redis 的 原生锁,SET key value NX PX ttl,key使用的设备维度lock:device:{Sn},value使用的随机token
NX:只有当 key 不存在时才设置成功PX ttl:给 key 设置过期时间,单位是毫秒。
加锁成功后,创建订单落库,把token存到订单表中的lock_token字段
解锁的时候,通过订单号查询Sn和lock_token两个字段,执行Lua解锁
1 | if redis.call('get', KEYS[1]) == ARGV[1] then |
没有使用Redisson看门狗机制,它要求JVM是在一个线程中(面试时不说,问了再说)
MySQL和Redis的双写一致性
1、Cache-Aside(旁路缓存):写更新库+删缓存,读缓存未命中查库回填,简单常用
2、延迟双删方案:先删除缓存,再更新数据库,延迟再删除一次缓存
3、canal订阅MySQL binlog日志 + MQ + 重试缓存删除
MQTT协议

设备服务调用通信服务给设备发指令:

设备给通信服务发送报文:

设备发送命令不稳定处理

xxl-job兜底
用户扫码 → 发送 MQ 延迟消息 → 1 分钟后检查是否授权
如果 MQ 延迟消息失败怎么办?
- xxl-job 定时任务兜底,看哪些订单长时间未授权,取消掉。
使用了什么设计模式?
✅单例模式
线程池中使用了单例模式,通过单例模式,确保线程池的唯一性,一般的业务的使用同一个单例的线程池,共享连接池,便于管理和监控
✅模板模式
BaseException:定义基础的异常抽象类,然后不同类型的异常再去实现基础异常类
✅工厂+策略模式
- 像我们的支付服务的支付方法,我们会把所有支付渠道中的公共代码抽取出来,定义一个抽象类
- 然后根据不同的支付渠道,定义多个实现类,策略服务
- 然后对这些不同的 payService 服务,使用工厂去统一管理,存到工厂中的 payServiceMap 中,当使用不同的渠道服务时,就调用它的 getPayService
接口限流有哪些方式?
- 漏桶:控制消费速度,来了先放链表后面,前面的慢慢消费
- 令牌桶:一秒就放 10 个令牌,能拿到就往下走
- 线程池:线程数量控制
- 信息量,semphore:但是只是单机的,集群限制 50 个该怎么做?Redis 中有一个集群化的semphore
使用Redisson的分布式信号量:
1 | // 初始化 |
- 自定义注解【建议的方法】
设置一个全平台注解,里面可以对IP进行校验,对于同一IP的请求,我们会给它设置800毫秒的时间限制,这样就可以让同一IP在一定时间内只能请求一次,其他请求全部拦截。
MySQL调优
建立索引
我们并不是一股脑加索引,而是使用慢SQL日志抓最慢 SQL,找到哪些SQL语句执行的比较慢,尽量做覆盖索引,避免 filesort 和回表。
像货柜订单列表这种高频接口,我们会围绕设备 sn、订单状态、创建时间建联合索引,例如 (device_sn, status, create_time),让最近订单查询从扫描全表变成走索引。
主库/从库 TIDB
我们只能货柜项目这个项目开始的数据量不大,就没有考虑过分库分表,但上线一年的时间里,目前已经有2个亿的数据了,主要的数据在订单表、订单详情表中
当数据量太大影响查询性能的时候,我们采用了tidb,主库+历史库的方式,tidb我们的leader也比较熟悉
对于订单表,我们现库保留三个月的数据,差不多1000w左右,历史库通过Cloadcanal伪装成MySQL的从库监听bin log实时同步到tidb中(具体的是dba做的)
tidb呢,作为分布式数据库,查询单表2亿的数据,性能可以到秒级
由于我们需要MySQL的事务能力,因此我们的主库还是MySQL,查询是去找tidb的历史库
建立唯一索引&&sql语句优化
建立唯一索引是因为高并发下,对于SELECT语句查询需求很大,同时等值查询(WHERE out_trade_no = ?)可以非常快定位,所以需要建立唯一
我们支付回调和 MQ 消费链路都可能重复触发,防止将多条脏数据存入数据库中,所以我们在数据库层做幂等。原本的方式是先判断有没有支付回调这条记录,没有的话再插入。但是后来发现如果回调量上来以后,数据库就会多很多”无意义的读“操作
1 | SELECT id FROM pay_callback WHERE out_trade_no = ?; |
所以后来我们就换了一种sql写法,首先将支付回调的Id,out_trade_no设置为唯一索引,用的是INSERT ... ON DUPLICATE KEY UPDATE,它会先判断数据库里没有这个 out_trade_no,没有正常插入一条新记录,有的话不报错!转而执行 UPDATE,把这条记录更新掉
1 | INSERT INTO pay_callback(out_trade_no, pay_status, raw_body, update_time) |
结果就是用一条 SQL完成“首次写入”+“重复来的更新”,并且是原子的。
JVM调优
✅做过。
-
最初设备就100台
-
后来设备越来越多,到了600台,通过排查(使用Leader搭建的可视化工具检查dump文件)发现持续发心跳 发重量 会导致通讯服务中的 Minor GC 非常频繁,而且晋升到老年代的速率很高(Survivor 装不下导致提前晋升),老年代增长很快,进而触发 Full GC。
-
CPU处理速度变慢或导致频繁的full GC
✅怎么解决?
-
首先把每个通信服务我们最多让它连接300台~500台设备,新增的设备连到新的通信服务上。
-
通信服务做了集群,一共5台,缓存记录了每台设备连接的是哪些通信服务
-
正常情况下,老年代 : 新生代 = 2:1 将其调成 老年代:新生代 = 1:1。这是因为我们的对象大多是短命的,把 新生代 做大能降低 Minor GC 频率,让短命对象在 Eden 直接死掉,减少 GC 压力。
-XX:NewRatio=2代表 老年代:新生代 = 2:1(默认常见值之一)
-XX:NewRatio=1代表 老年代:新生代 = 1:1
- 再将新生代的 Eden : Survivor : Survivor = 8 : 1 : 1 改成 Eden : Survivor : Survivor = 3 : 1 : 1。这是因为有一部分对象会跨过 1~2 次 GC,如果 Survivor 太小就会被迫提前晋升到 Old。把 Survivor 做大可以降低晋升率,让这类对象在 新生代 里自然消亡。
-XX:SurvivorRatio=8代表 Eden : Survivor = 8 : 1(两个 Survivor 各 1)
-XX:SurvivorRatio=3代表 Eden : Survivor = 3 : 1
修改以后,查看 GC 日志里的 promotion rate(晋升量)、Old 使用曲线和 Full GC 次数,确认 Survivor 调整确实降低了提前晋升。
✅GC 日志:时间序列的“过程记录”(频率、停顿、内存变化趋势)
✅Heap Dump:某一时刻的“静态快照”(对象分布、引用链、泄漏定位)
用一个小例子帮你建立直觉 🌰
你发现服务卡顿:
- 你先看 GC 日志:发现 Full GC 很频繁,每次停顿 1s+
→ 说明“GC 行为有问题”,但还不知道“是谁占内存”。- 然后打 Heap Dump:发现某个
Map里堆了几百万条设备心跳对象,被某个缓存引用着没释放
→ 你就知道“是谁导致老年代涨”,可以去改代码或限流。
三、数据库
设备表
1 | CREATE TABLE `device_info` ( |




