
JVM八股文
JVM模型
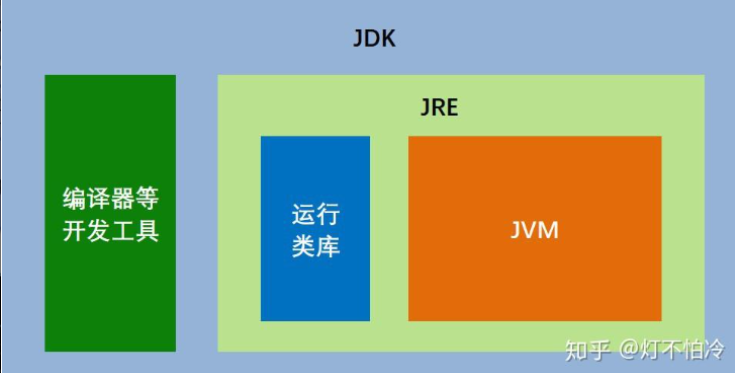
- JDK:Java Development Kit:Java开发工具包
- JRE:Java Runtime Environment:Java运行环境
- JVM:Java Virtual Machine Java虚拟机
为什么要引入JVM?
- JVM是Java虚拟机,支持跨平台运行,一次编译,处处运行,它能识别.class后缀文件,解析它的指令,完成想要的操作
- 内置GC回收垃圾,不需要手动管理内存
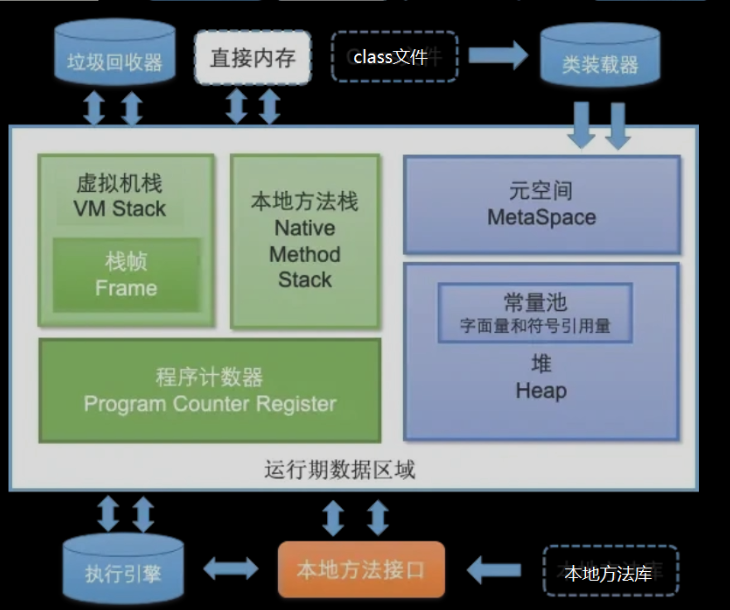
JVM运行时内存共分为
JVM 运行时内存主要分为 线程私有 和 线程共享 两类。
线程私有的包括:
- 程序计数器
- Java 虚拟机栈
- 本地方法栈
线程共享的包括:
- 堆
- 方法区(JDK 8 以后是元空间,使用本地内存)
- 程序计数器
用于存储当前线程正在执行的java方法JVM指令地址;如果执行Native,计数器为null
程序计数器的作用,为什么是私有的?
程序计数器用于记录当前线程正在执行的字节码指令地址,在线程发生时间片切换时,JVM 可以根据程序计数器恢复执行位置。因为每个线程执行进度不同,所以程序计数器必须是线程私有的。
- Java虚拟机栈
每个线程都有自己独立的java虚拟机栈,生命周期与线程相同。每个方法在执行时都会创建一个栈帧。可能会抛出StackOverflowError和OutOfMemoryError异常
- 本地方法栈
使用Native方法服务,可以调用其他语言,比如C++;本地方法执行时也会创建栈帧
- 堆
JVM中最大的一块内存区域,被所有线程共享,在虚拟机启动时创建,用于存放对象实例
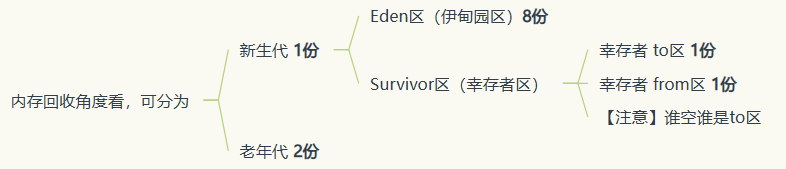
-
新生代:老年代 = 1:2
-
Eden:Survivor = 8:1: 1
如果在堆中没有内存完成实例分配,堆也无法扩展时会抛出 OutOfMemoryError 异常
- 元空间(方法区)
- 在JDK6叫永久代
- 在JDK7还叫永久代,但是放到堆中了
- 在JDK1.8后,叫元空间,移动到本地内存中
用于存储已经被虚拟机加载的类信息、常量等数据,元空间可以不实现垃圾收集,内存不足时会抛出OutOfMemoryError
堆、栈
JVM内存模型中的堆和栈有什么区别?
【栈】
- 用途:每当一个方法被调用,一个栈帧就会在栈中创建,用于存储该方法的信息,当方法执行完毕,栈帧也会被移除
- 生命周期:有具体的生命周期,当一个方法调用结束后,其对应的栈帧就会被销毁,栈中存储的局部变量随之消失
- 存取速度:比较快,栈遵循先进后出的原则,操作简单快速
- 存储空间:栈的空间相对较小,且固定,由操作系统管理,栈溢出通常由于递归过深或局部变量过大(无限长的String)
- 可见性:私有的,每个线程有自己的栈空间
【堆】
- 用途:用于存储对象的实例(包括类的实例和数组),当使用new关键字创建一个对象时,对象的示例就会在堆上分配空间
- 生命周期:生命周期不确定,对象会在垃圾回收机制检测到对象不再被引用时才被回收
- 存取速度:比较慢,对象在堆上分配和回收需要更多时间,而且垃圾回收机制的运行也会影响性能
- 存储空间:堆的空间相对较大,动态扩展,由JVM管理,堆溢出通常由于未能及时回收不再使用的对象
- 可见性:共享的,所有线程都可以访问堆上的对象
堆分为哪几部分?
- 新生代、老年代

- 新生代
Eden Space:大多数新创建的对象首先会存放在这里,Eden区相对较小,当Eden区满时,会触发一次Minor GC(新生代垃圾回收)
Survivor Space:细分为Survivor to、Survivor from这两个区;每次Minor GC后,存活下来的对象会被移动到其中一个Survivor空间,继续它们的生命周期,这两个区域轮流充当对象的中转站
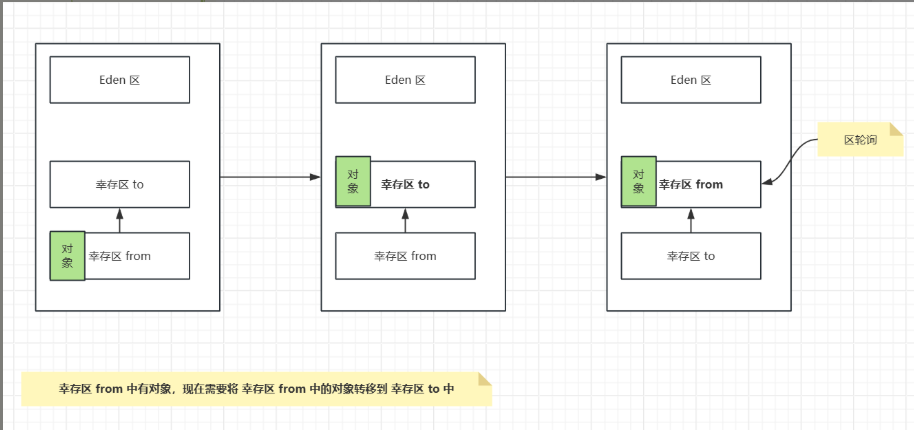
- 老年代
新生代对象经历15次Minor GC仍存活的对象,就会从Survivor区移动到老年代。老年代中的对象生命周期较长,因此Major GC(老年代的垃圾回收)发生频率较低,但执行时间通常比Minor GC长。老年代的空间通常比新生代大,以存储更多的长期存活对象
为什么是15次?
因为对象的Java对象头Mark Word中的GC标记是四位二进制数
1111,最大就15次
- 元空间(方法区)
Java 8开始,永久代被元空间取代,用于存储类的结构信息(如字段、方法信息),元空间并不在Java堆中,而是使用本地内存,解决了永久代容易出现的内存溢出问题
- 大对象区
在某些JVM实现中(如G1垃圾收集器),为大对象分配了专门大的区域,大对象是指需要大量连续内存空间的对象,如大数组,这类对象直接分配在老年代,以免频繁因为年轻代晋升而导致内存碎片化问题
TLAB机制?
Thread Local Allocation Buffer(TLAB)
Eden是线程共享的区域,如果多个线程同时分配去操作Eden的同一块连续内存,就会有线程安全的问题。为了减少线程竞争,JVM给每个线程划分了一块属于自己的堆内存,创建对象时,就可以用线程的私有堆区(TLAB)分配对象,减少锁竞争。70~80%的对象内存分配都是来自己线程自己的TLAB
栈中存的到底是指针还是对象?
栈中存储的不是对象,而是对象的引用,当声明一个对象:MyObject obj = new MyObject();时,这里的obj实际上是存储在栈上的引用,实际指向堆中的对象实例内存空间
方法区(也叫元空间)
方法区是 JVM 规范中定义的一块线程共享区域,主要用来存储类的元数据信息、运行时常量池、静态变量以及部分编译后的代码。
在 HotSpot 里,JDK 7 以前用永久代来实现方法区,从 JDK 8 开始改用元空间,通过本地内存存放这些类元数据。方法区本身是可以被 GC 的,比如在类卸载的时候,其对应的元数据和常量池就会被回收。
当一个方法被调用时,JVM 如何利用方法区中的方法元数据来完成一次方法调用与执行?
当程序中通过对象或类直接调用某个方法时,主要包括以下几个步骤:
- 解析方法调用:JVM会根据方法的引用找到实际的方法地址
- 栈帧创建:在调用方法之前,JVM会在当前线程的Java虚拟机栈中为该方法分配一个新的栈帧,栈帧用于存储局部变量表,操作数栈,方法出口等信息
- 执行方法:执行方法内的字节码指令
- 返回处理:方法执行完毕后,可能会返回一个结果给调用者,并清理当前栈帧,恢复调用者执行环境
方法区中还有哪些东西?
- 类信息:包括类的结构信息、类的访问修饰符、父类与接口等信息
- 常量池:存储类和接口中的常量,包括字面值常量、符号引用,以及运行时常量池
- 方法字节码:存储类的方法字节码,即编译后的代码
- 静态变量:存储类的静态变量,这些变量在类初始化的时候被赋值
- 符号引用:存储类和方法的符号引用,是一种直接引用不同于直接引用的引用类型
- 运行时常量池:存储着在类文件中的常量池数据,在类加载后在方法区生成该运行时常量池
- 常量池缓存:用于提升类加载的效率,将常用的常量缓存起来方便使用
String s = new String(“abc”)执行过程中分别对应哪些内存区域?
String保存在哪?
String保存在字符串常量池中,不同于其他对象,它的值是不可变的,且可以被多个引用共享
对应堆中的区域:
- 如果abc这个字符串常量不存在,则创建两个对象,分别是abc这个字符串常量,以及new String这个实例对象
- 如果abc这字符串常量存在,则只会创建一个对象
引用类型
引用类型有哪些?有什么区别?
- 强引用:代码中普遍存在的赋值方式,比如
A a = new A(),强引用关联的对象,永远不会被GC回收 - 软引用:指有用但是,不是必须要的对象,系统在发生内存溢出前会对这类引用的对象进行回收
- 弱引用:它的对象下一次GC的时候,一定会被回收,而不管内存是否足够
- 虚引用:必须和ReferenceQueue一起使用,同样当发生GC的时候,虚引用也会被回收
弱引用了解吗?举例说明在哪里可以用?
弱引用是一种引用类型,它不会阻止一个对象被垃圾回收,主要用途是创建非强制性的对象引用,这些引用可以在内存压力大时被垃圾回收期清理,从而避免内存泄漏
使用场景:
- 缓存系统:弱引用常用于实现缓存,特别是当希望缓存项能够在内存压力下自动释放时,使用弱引用来维护缓存,可以让JVM在需要更多内存时自动清理这些缓存对象
- 对象池:在对象池中,弱引用可以用来管理哪些暂时不使用的对象,当对象不再被强引用时,它们可以被垃圾回收,释放内存
- 避免内存泄漏:当一个对象不应该被长期引用时,使用弱引用可以防止该对象被意外保留,从而避免潜在的内存泄漏
内存泄漏、内存溢出
内存泄漏和内存溢出的理解
- 内存泄漏
程序在运行过程中不再使用的对象任然被引用,从而无法被垃圾收集器回收,从而导致可用内存减少
常见原因:
- 静态集合:使用静态数据结构(如 HashMap 或 ArrayList )存储对象,且未清理
- 事件监听:未取消对事件源的监听,导致对象持续被引用
- 线程:未停止的线程可能持有对象引用,无法被回收
- 内存溢出
Java虚拟机(JVM)在申请内存时,无法找到足够的内存,最终引发 OutOfMemoryError ,常见在堆内存不足、存放新创建的对象时
常见原因:
- 大量对象创建:程序不断创建大量对象,超出JVM堆的限制
- 持久引用:大型数据结构(如缓存、集合等)长时间持有对象引用,导致内存累积
- 递归调用:深度递归导致栈溢出
JVM内存结构有哪几种内存溢出的情况?
-
堆内存溢出:代码中可能存在大对象分配,或者发生了内存泄漏,导致多次GC之后,还是无法找到一块足够大的内存容纳当前对象
-
栈溢出:写一段程序不断地进行递归调用,而且没有退出条件,导致不断地进行压栈
-
元空间溢出:系统的代码非常多或引用的第三方包非常多等方法,导致元空间的内存占用很大
-
直接内存内存溢出:在使用ByteBuffer中allocateDirect()的时候会用到,很多NIO框架中被封装的其他方法,出现内存溢出
具体内存泄漏例子和解决方案?
- 静态属性导致内存泄漏
大量使用static静态变量,不再需要的对象,还被强引用着,导致越堆越多
1 | public static List<Double> list = new ArrayList<>(); |
解决方案:减少静态变量使用,如果使用单例,尽量采用懒加载(饿汉式)
- 未关闭的资源
创建一个链接或打开一个流,JVM都会分配内存给这些资源;比如数据库连接、输入流和session对象,忘记关闭这些资源,会阻塞内存,导致GC无法进行清理
解决方案:记得在finally中进行资源的关闭,或者使用try-with-resources代码进行资源关闭
类加载(Java对象加载)
Java 对象创建过程

- 类加载检查
虚拟机遇见一条new指令时,先检查这个指令的参数能否在常量池中定位到一个类的符号引用,检查这个符号引用的类是否已经被加载过、解析和初始化过,如果没有,必须执行相应的类加载过程(加载、链接、初始化)
- 分配内存
在类加载检查通过后,接下来虚拟机将为新生对象分配内存,对象所需的内存大小在类加载完成后可确定,将确定大小的内存从堆中划分出来
- 初始化零值
内存分配完毕后,虚拟机会将对象头之外的那片字段区域全部清零,确保了不用赋初值就能进行访问
- 进行必要设置,比如对象头
对对象进行必要的设置,例如将下面的信息存储在对象头中
- 这个对象是哪个类的实例
- 对象的哈希码
- 对象的GC分代年龄等信息
- 执行init方法
进行初始化,将一个真正可用的对象构造出来
类加载器有哪些?
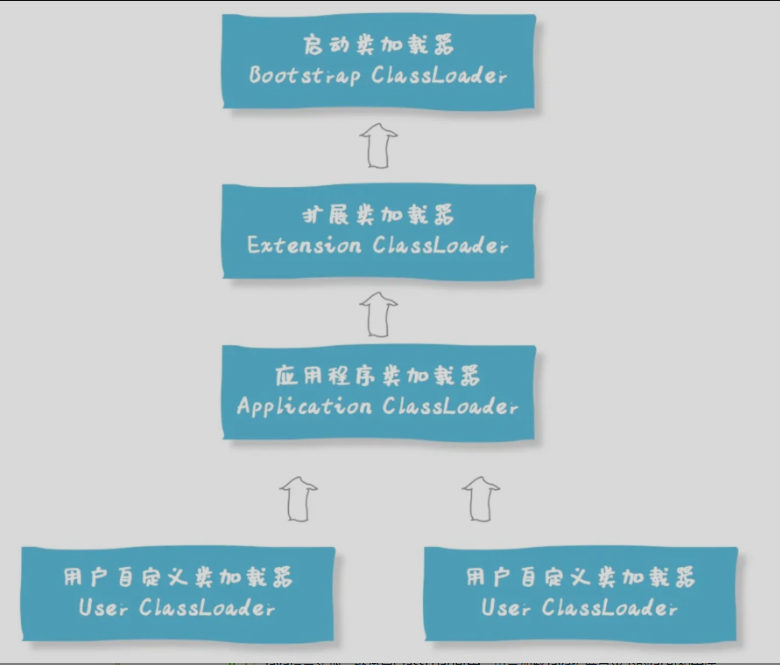
- 启动类加载器
最顶层的类加载器,负责加载Java的核心库,用C++编写的,是JVM的一部分,启动类加载器无法被Java程序直接使用
-
加载 JAVA_HOME/jre/lib/
-
从JDK9开始,变为加载 /lib/modules 文件
- 扩展类加载器
Java语言实现,继承自ClassLoader类,负责加载Java扩展目录下的jar包和类库,由启动类加载器加载。(它的父加载器就是启动类加载器)
- 加载 /jre/lib/ext/
- 从JDK9开始,变为加载 /lib/ext/
- 系统类加载器/应用程序类加载器
Java语言实现,负责加载用户类路径上的指定类库,是平时编写Java程序时默认使用的类加载器。(它的父加载器是扩展类加载器)
- 自定义类加载器
开发者可以根据需求定制类的加载方式,比如从网络加载class文件、数据库中加载类,自定义类加载器可以用来扩展Java应用程序的灵活性和安全性
类的加载过程
类被加载到虚拟机内存开始,到卸载出内存为止,一共经历了7个阶段
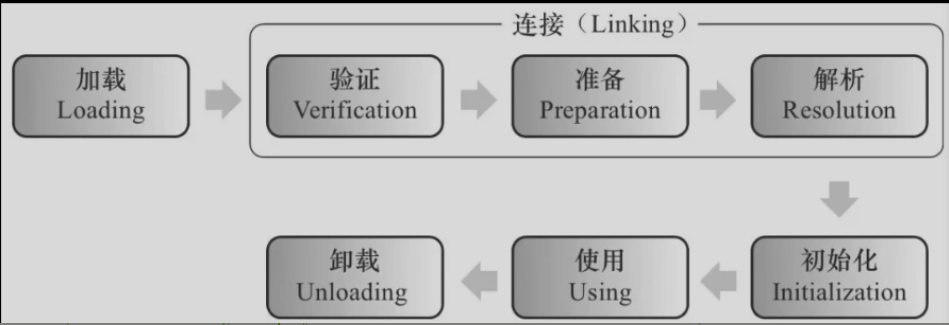
- 加载:通过类的包名 + 类名,加载字节码 → JVM 创建 Class 对象 → 放入方法区
- 连接
验证:保证这个被加载的class类的正确性,不会危害到虚拟机的安全
准备:未类中的静态字段分配内存,并设置默认的初始值;比如int类型初始值是0,被final修饰的static字段不会设置,因为final在编译的时候就分配了
解析:虚拟机将常量池中的符号引用直接替换为直接引用
符号引用:以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要可以无歧义的到达目标位置即可
直接引用:直接指向目标的指针
- 初始化:类加载过程最后一个阶段,简单来说就是执行编译器自动生成的构造方法
- 使用:使用类或者创建对象
- 卸载
有下面的情况,类就会被卸载
- 该类所有的实例已经被回收了,也就是Java堆中不存在该类的任何实例
- 加载该类的ClassLoader已经被回收
- 类对应的Java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法
双亲委派模型的作用
当一个类加载器收到类加载的请求时,首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,保证一个类只被加载一次,同时防止了JDK的核心类被篡改
作用:
-
保证类的唯一性:确保了所有加载请求都会传递到启动类加载器,避免了不同类加载器重复加载相同类的情况,保证了Java核心类库的统一性,防止了用户自定义类覆盖核心类库的可能
-
保证安全性:启动类加载器只加载信任的类路径中的类,这样可以防止不可信的类假冒核心类,增强了系统的安全性。例如,恶意代码无法自定义一个Java.lang.System类,并加载到JVM中
-
简化了加载流程:大部分类能被正确的类加载器加载,减少了每个加载器需要处理的类的数量,简化了类的加载过程,提高加载效率
-
支持隔离和层次划分
支持不同的类加载器服务不同的类加载需求
比如
- 应用程序类加载器加载用户代码
- 扩展类加载器加载扩展框架
- 启动类加载器加载核心库
有助于实现沙箱安全机制,保证了各个层级类加载器的职责清晰,便于维护和扩展
沙箱安全机制:把不可信代码关在 JVM 里的“围栏”里,只给它有限权限做事。
打破双亲委派的方法有哪些?
- 利用SPI机制:Service Provider Interface,java提供的,用于动态加载第3方服务实现类的机制,核心方法ServiceLoader.load(接口的java.lang.Class对象)
- 重写ClassLoader抽象类的loadClass方法
为什么要打破双亲委派?
JDBC中不同数据库厂商提供驱动类加载到用户自己写的代码业务中
对象的生命周期
- 创建:通过关键字new在堆内存中被实例化,对象的内存空间被分配
- 使用:对象被引用并执行相应的操作,在程序运行过程中被不断使用
- 销毁:当对象不再被引用时,通过垃圾回收机制自动回收对象所占用的内存空间
垃圾回收
什么是Java里的垃圾回收?
垃圾回收(Garbage Collection,GC)是自动管理内存的一种机制,它负责自动释放不再被程序引用的对象所占用的空间,这样减少了内存泄漏和内存管理错误的可能性
如何触发垃圾回收?
- 内存不足时:当JVM检测到堆内存不足,无法为新的对象分配内存时,会自动触发垃圾回收
- 手动请求:可以调用 System.gc() 或 Runtime.getRuntime().gc() 手动回收,但不能保证立即执行
- JVM参数:通过JVM调参,
-Xmx(最大堆大小)、-Xms(初始堆大小) - 对象数量或内存使用达到阈值:垃圾收集器内部实现类一些策略
判断垃圾的方法有哪些?
- 引用计数法
原理:为每一个对象分配一个引用计数器,每当有一个地方引用它时,计数器加1,当引用失效时,计数器减1,当计数器为0时,表示对象不再被任何变量引用,可以被回收
- 可达性分析算法
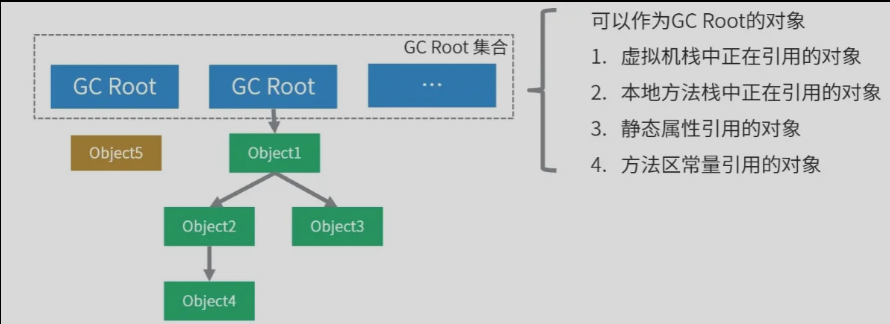
原理:从一组GC Root(垃圾收集根)的对象出发,向下追溯它们引用的对象,以及这些对象引用的其他对象,如果一个对象到GC Root集合没有任何引用链相连(也就是说从GC Root集合不能到这个对象),那么这个对象被认为不可达,可以被回收
CMS垃圾回收过程
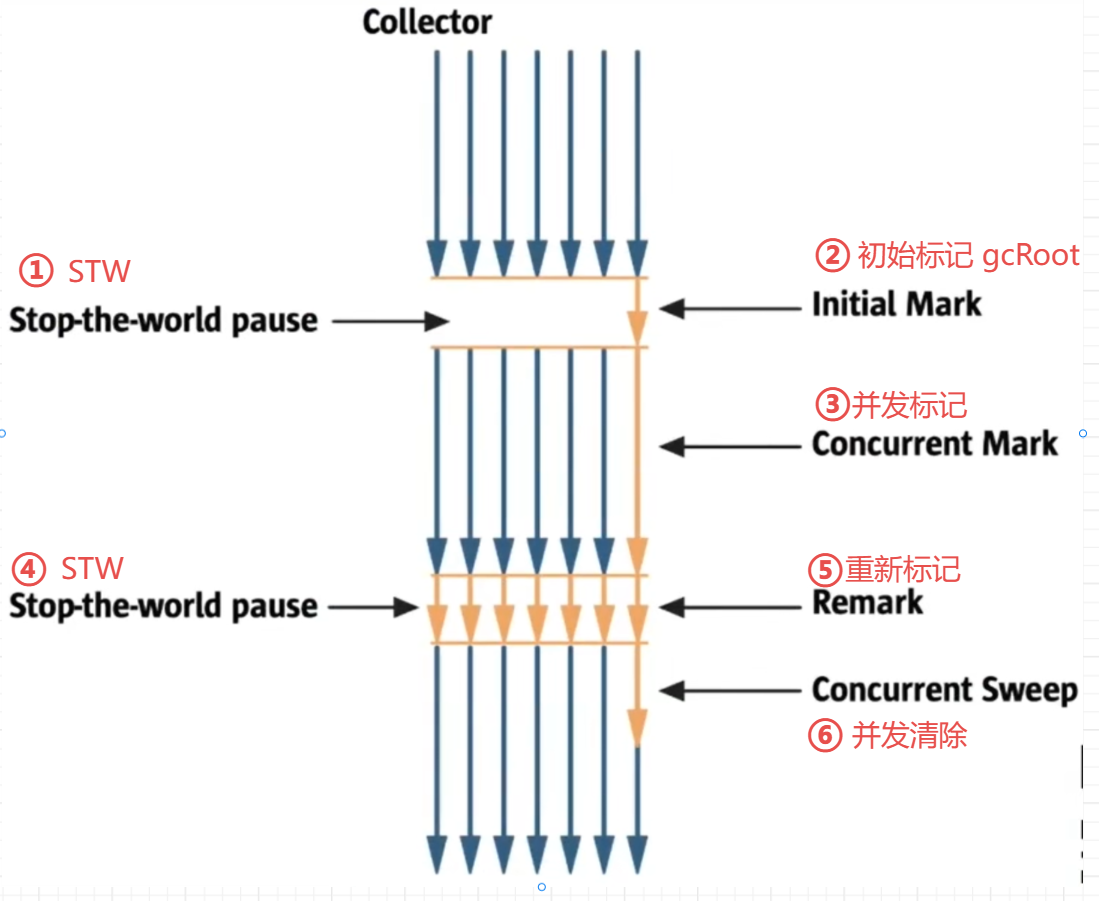
首先短暂的STW,通过gcRoot进行初始标记;之后和其他线程一起跑进行并发标记;标记完后短暂的STW,重新标记,因为并发标记的时候其他线程可能有什么修改,短暂的重新标记确认一下;最后并发清除
垃圾回收算法是什么?为了解决什么?
垃圾回收机制主要目标是自动检测和回收不再使用的对象,从而释放它们的内存空间,这样可以避免内存泄漏,同时也可以防止内存溢出
垃圾回收算法有哪些?
- 标记-清除算法
分为“标记”和“清除”两个阶段,通过可达性分析,标记出所有需要回收的对象,再统一回收所有被标记的对象
【主要在老年代】
缺点:效率不高,清除后会造成大量的碎片空间,可能造成申请大块内存的时候没有足够的连续空间导致再次GC
- 复制算法
为了解决碎片空间问题,引入复制算法,将内存分成两块,每次申请内存时都使用其中一块,当内存不够时,将A块内存中所有存活的复制到B块上,然后将A块使用的内存整个清理掉
【主要在新生代】,Survivor 0 / 1 是给“复制算法(拷贝算法)”用的
缺点:内存利用率严重不足
- 标记-整理算法
复制算法在GC之后存活对象较少时效率高,但是存活对象一多,进行复制操作,效率就会下降,标记之后不会直接清理,而是将所有存活的对象直接移动到内存的一段,移动结束后直接清理剩余部分
【主要在老年代】
它与标记-清除算法不同的是
标记-清除(Mark-Sweep):标记活的,把死的直接清掉,不挪活对象。结果:会碎片化
标记-整理(Mark-Compact):标记活的,然后把活的往一边挪紧,再清理尾部。结果:无碎片,但要搬家
- 分代回收算法
将内存划分成了新生代和老年代,对象创建时,一般在新生代申请内存,当经历一次GC之后如果还存活,那么对象年龄+1,当年龄超过一定值(默认是15,可以通过 -XX:MaxTenuringThreshold 来设定),如果对象还存活,那么该对象会进入老年代
垃圾回收器有哪些?
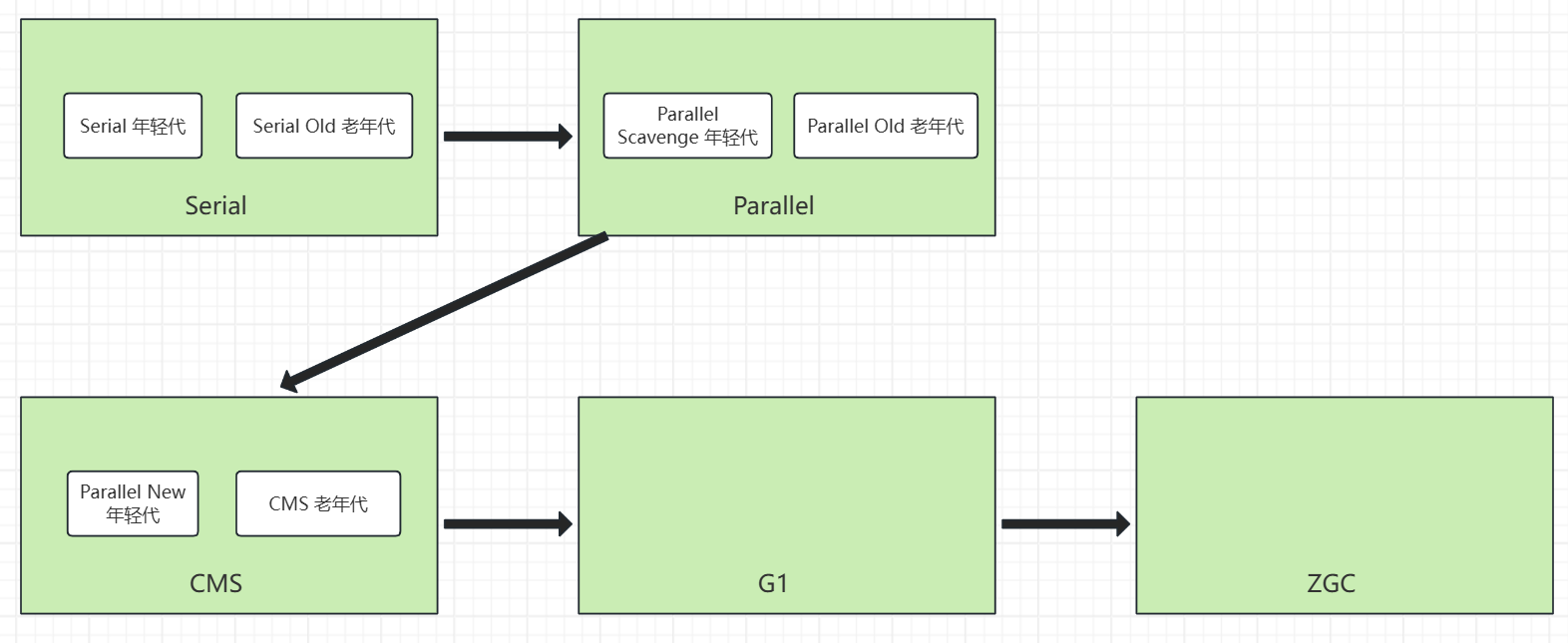
年轻代的垃圾回收机制都是:复制算法
- Serial串行
年轻代、老年代将所有线程停止,再创建一个单线程进行垃圾回收
老年代使用的是标记清除算法。
- Parallel并行
年轻代、老年代将所有线程停止,再创建多线程程进行垃圾回收
老年代使用的是并行标记整理算法。
- CMS(已被舍弃)
对于老年代使用CMS,年轻代配合新创建了Parallel New
老年代使用的是标记清除算法。
- G1
老年代使用的是标记整理算法。
- ZGC
指针碰撞是什么?
在一片连续的内存中,维护一个“顶端指针”,当需要给新对象腾出一片内存空间,只需要将顶端指针往后移动,将移动留出的空间给新对象

标记清除算法的缺点是什么?
- 效率问题:标记和清除效率都不高
- 空间问题:标记清除后会产生大量不连续的内存碎片,此时运行过程中需要分配较大的对象,而无法找到连续的大量内存空间,不得已提前触发一次GC
垃圾回收算法哪些阶段会stop the world(STW)?
STW(Stop-The-World):垃圾回收(GC)过程中,JVM 暂停所有应用线程,只有垃圾回收线程运行,以确保内存状态一致性。
触发场景:
- Young GC:Minor GC 时短暂 STW(通常毫秒级)
- Full GC:Major GC 时长时间 STW(可能秒级甚至更长)
- 元空间/方法区回收、堆外内存回收等。
为什么需要STW?
- 为了防止GC过程中引用关系被破坏
- 确保对象复制或移动时引用正确
- 保证垃圾对象识别的准确性
minorGC、majorGC、fullGC的区别,什么场景触发full GC
根据其作用范围和触发条件的不同,可以将GC分为三种类型:Minor GC、Major GC、Full GC
- Minor GC
作用范围:只针对年轻代进行回收,包括Eden区和两个Survivor区(S0和S1)
触发条件:当Eden区空间不足时,JVM会触发一次Minor GC,将Eden区和一个Survivor区中的存活对象移动到另一个Survivor区或老年代
特点:通常发生得非常频繁,因为年轻代中对象的生命周期较短,回收效率高,暂停时间相对较短
- Major GC
作用范围:主要针对老年代进行回收,但不一定只回收老年代
触发条件:当老年代空间不足时,或者系统检测到年轻代对象晋升到老年代速度过快,可能会触发Major GC
特点:发生频率较低,每次回收时间长,因为老年代中的对象存活率较高
- Full GC
作用范围:**对整个堆内存(包括年轻代、老年代、永久代/元空间)**进行回收
触发条件
- 直接调用 System.gc() 或 Runtime.getRuntime().gc() 方法时,不一定立即执行,但JVM会尝试执行Full GC
- Minor GC时,如果存活对象无法放入老年代,或者老年代空间不足时,会触发Full GC,对整个堆内存进行回收
- 当永久代(Java 8之前的)/元空间(java 8 及以后) 空间不足时
特点:需要停止所有工程线程,遍历整个堆内存来查找和回收不再使用的对象,因此尽量减少Full GC的触发
Full GC是发生OOM前的最后一次挣扎
空间担保机制
空间分配担保是 Minor GC 前对‘对象晋升到老年代’的风险评估:看老年代最大连续可用空间,够则 Minor GC,不够则可能先/转 Full GC,避免晋升失败。
垃圾回收器CMS和G1的区别?
- CMS
使用范围不一样:CMS收集器是老年代的收集器,可以配合新生代的Serial和ParNew收集器一起使用
STW时间:CMS收集器以最小的停顿时间为目标
垃圾碎片:CMS收集器使用 “标记-清除” 算法进行垃圾回收,容易产生内存碎片
回收过程不一样,主要体现在:标记-清除(Mark-Sweep):标记活的,把死的直接清掉,不挪活对象。结果:会碎片化
浮动垃圾:CMS产生浮动垃圾过多时会退化为serial old,效率低
- G1
使用范围不一样:G1收集器收集范围是老年代和新生代,不需要配合其他收集器使用
STW时间:G1收集器可以预测垃圾回收的停顿时间
垃圾碎片:G1收集器使用 “标记-整理” 算法,进行了空间整合,没有内存空间碎片
回收过程不一样,主要体现在:标记-整理(Mark-Compact):标记活的,然后把活的往一边挪紧,再清理尾部。结果:无碎片,但要搬家
浮动垃圾:G1没有浮动垃圾的回收
什么情况下使用CMS,什么情况使用G1?
- CMS
低延迟需求:适用于对停顿时间要求敏感的应用程序
老生代收集:主要针对老年代的垃圾回收
碎片化管理:容易出现内存碎片,需要定期进行Full GC来压缩内存空间
- CMS 适合老版本 JDK + 对老年代停顿敏感
- G1
大堆内存:适用于需要管理大内存堆的场景,能够有效处理 几GB 以上的堆内存
对内存碎片敏感:G1通过紧凑整理来减少内存碎片,降低了碎片化对性能的影响
比较平衡的性能:G1在提供较低停顿时间的同时,也保持了相对较高的吞吐量
- G1 更适合 **大堆 / 讲究停顿时间 **,而且在现代 JDK 里已经成为默认的 server GC 选择。
G1回收期的特点是什么?
特点
- G1最大的特点就是引入分区的思路,弱化了分代的概念
- 合理利用垃圾收集各个周期的资源,解决了其他收集器的众多缺点
G1相比较CMS的改进
- 算法:G1基于 标记-整理 算法,不会产生空间碎片,在分配大对象时,不会因为找不到一大片连续的空间,而提前触发一次Full GC
- 停顿时间STW可控:G1可以设置预期停顿时间来控制垃圾收集时间,以避免雪崩现象
- 并行与并发:G1能更充分利用CPU多核,缩短STW的停顿时间
GC只会对堆进行GC吗?
不是,还会对方法区进行垃圾回收,方法区存储类信息、常量、静态变量等数据;虽然方法区中垃圾回收与堆有所不同,但是同样存在 对不再需要的常量、无用的类信息等进行清理
finalize()方法
设计初衷是让对象GC前能有时间进行资源关闭,每当发生GC就会自动执行该方法,相当于一个钩子方法
但是有一系列隐患(依赖于GC执行,时机不确定,可能让已经成为垃圾的对象“复活”,造成内存泄漏),JDK9弃用,尽量不要使用它
new出来的对象一定在堆里面吗?
不一定,有可能出现方法逃逸
方法逃逸只在当前方法里用,没有被方法以外的变量所引用,用完就丢,不返回、不存到字段、不放集合里,说明只有在当前方法中存在,用完了就被优化掉,不进堆
JMM
什么是JMM?
- Java Memory Model:Java内存模型
- 由于硬件和操作系统的不同,内存的访问有一定的差异;所以引入JMM屏蔽掉各种硬件和操作系统的内存访问差异,让Java程序在各个平台下都可以达到一致的并发效果
- JMM规定所有变量都存储在主存中
- 包括实例变量、静态变量
- 不包括局部变量和方法参数
- 每个线程都有自己工作内存,线程的保存了该线程用到的变量和主内存的副本拷贝,线程对变量的操作都在工作内存中进行;线程不能直接读取主内存中的变量
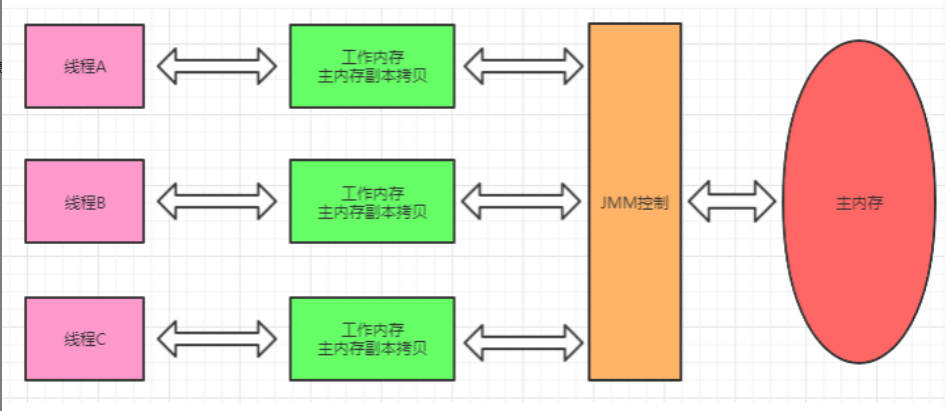
JMM定义了什么?
整个JMM实际上围绕着三个特征建立起来的
- 原子性:指一个操作是不可分割,不可中断的,一个线程在执行时不会被其他线程干扰
- 可见性
一个线程修改共享变量的值,其他线程能够立即知道值被修改了
实现方式:
- volatile关键字:被volatile修饰的变量,被修改后会立刻刷新到主内存,当其他线程需要读取的时候,会从主内存中读取最新值
- synchronized:执行完,进入unlock之前,JMM 保证释放锁之前的写,对之后获得同一把锁的线程一定可见,不允许出现旧值。
- 有序性:可以使用synchronized或者volatile保证多线程之间操作的有序性
指令重排
是什么?
为了提高效率,编译器和处理器会在不影响单线程执行结果前提下,对指令的执行顺序进行重新排序
指令重排有限制吗?
有限制,限制就是 happens-before 原则,如果 A happens-before B,那么 A 的结果(内存写入)对 B 可见
as-if-serial又是什么?
- 不管怎么重排序,单线程程序的执行结果不能被改变
- 编译器和处理器为了优化性能可以尽情重排指令,但必须保证最终结果和代码顺序执行的结果一致
单线程的程序一定是顺序的吗?
单线程的程序在最终执行效果上是有序的,但底层的执行过程不一定是顺序的,很可能已经被优化重排过了。只是我们感知不到这个重排带来的差异。




