python模块与包
模块化与包
1 模块概述
Python 中一个以.py结尾的源文件即为一个模块(Module),内部可包含变量、函数、类、常量等代码实体。将特定功能的代码封装为模块,核心价值在于:
- 复用性:编写一次可在多个项目中导入使用,避免重复编码
- 可维护性:单个模块聚焦单一功能,便于调试和迭代
- 命名隔离:不同模块中可存在同名函数 / 变量,互不干扰
- 工程化:大型项目通过模块拆分实现分工协作,降低复杂度
模块名遵循标识符命名规则,严禁与 Python 标准库(如os、sys)或第三方库重名,否则会引发命名冲突。
2 模块创建
模块名区分大小写,且不能与 Python 自带的标准模块重名。
命名总结
1 | 标准 Python 代码中仍推荐使用蛇形命名法 |
2.1 基础模块创建
创建一个模块my_add.py
1 | num =100 |
2.2 模块设计最佳实践
-
文档字符串:模块开头添加功能说明,函数 / 类添加用途、参数、返回值注释
-
类型注解:为函数参数和返回值添加类型提示,提升可读性和 IDE 支持
-
私有成员:内部辅助函数 / 变量以单下划线
_开头,对外隐藏实现细节 -
自测代码:通过
if __name__ == "__main__"编写模块自测逻辑,不影响导入使用1
2if __name__ == "__main__":
print("模块自测") -
常量命名:模块级常量使用全大写 + 下划线命名(如
MAX_RETRY)
练习,有如下需求:
定义数学工具模块math_tools
- 基础算术运算函数
- add(a: int | float, b: int | float) -> int | float
功能:计算两个数的和
参数:两个数值类型参数 a 和 b
返回值:两数之和- multiply(a: int | float, b: int | float) -> int | float
功能:计算两个数的乘积
参数:两个数值类型参数 a 和 b
返回值:两数之积- 数列计算函数
- fibonacci(n: int) -> int
功能:计算斐波那契数列第n项的值
参数:非负整数 n(项数)
返回值:斐波那契数列第n项的数值
异常处理:当输入负数时抛出 ValueError- 数学常量
- PI:圆周率常量,值为3.1415926535
- EULER:自然常数e,值为2.7182818284
- 辅助函数,用于将计算结果格式化,小数保留2位
- _format_number(n: int | float) -> str
功能:格式化数字显示(内部私有函数)
参数:数值类型参数 n
返回值:格式化后的字符串- 给与自测方法
实现:一个功能完整的数学工具模块示例(math_tools.py):
1 | """ |
3 导入模块
导入操作需要在另外一个模块中操作:
同级目录创建main.py,本节案例均在main.py中导入上个案例练习中的math_tools,并使用
3.1 全部导入 import
导入模块所有成员,通过模块名.成员名访问,适合需要使用模块多个功能的场景,同一模块多次导入仅生效一次。
语法:
import 模块名 [as 别名]
3.1.1 基础用法
1 | # 导入模块 |
3.1.2 别名导入(解决命名冲突)
当模块名过长或存在命名冲突时,可指定别名:
1 | # 导入时指定别名 |
2
3
4
5
6
7
8
当前模块使用以下方式获取dict内容
print(globals())
print(sys.modules[__name__].__dict__)
import __main__
print(__main__.__dict__)
3.2 局部导入(from...import)
指定导入模块的部分成员,直接通过成员名访问,减少代码冗余,重名成员后导入会覆盖前导入。
3.2.1 导入特定成员
语法:from 模块名 import 成员名1[as 别名], 成员名2[as 别名],…
1 | # 导入模块中的指定函数和常量 |
3.2.2 别名避免冲突
1 | # 导入时为成员指定别名(解决同名冲突) |
3.3 全部局部导入(from...import *)
导入模块中所有非单下划线开头的成员,适合临时测试或快速使用模块全部功能。
- 语法:
from 模块名 import * - 案例:
1 | from my_add import * |
3.4 导入方式区别与选择
3.4.1 导入区别
- 命名空间影响:
- import 模块:将模块对象本身放入当前命名空间,使用需加前缀(如:模块.成员)。
- from 模块 import 名称:把指定名称直接放入当前命名空间,使用时无需模块前缀。
- **from 模块 import *:把模块中“公开”的名称批量放入当前命名空间;若模块定义了 all,则只导入列表中的名称;若未定义,通常导入所有不以下划线 _**开头的名称。此方式不会把“模块对象本身”带入命名空间(即不能写“模块.成员”)。
- 可读性与可维护性:
- 直接 import 能清晰看出成员来源,便于追踪与重构;
- import * 可读性差,易造成名称来源不明确与维护困难。
- 命名冲突与遮蔽:
- import 通过前缀隔离,冲突少;
- from … import(尤其是 *)容易与当前作用域名称冲突或被遮蔽。
- 性能与缓存:
- 两种方式都会利用 sys.modules 缓存,已导入模块不会重复执行;性能差异通常不明显,更多体现在可读性与维护性上
3.4.2 选择建议
如何选择更合适的方式
- 优先选择:import 模块 或 import 模块 as 别名。理由是来源清晰、命名空间干净、冲突少,长期维护成本更低。
- 可接受的选择:from 模块 import 名称1, 名称2。在明确只用到少量名称、且希望减少前缀冗余时使用;必要时配合 as 避免冲突。
- 尽量避免:**from 模块 import ***。仅在交互式会话或文档明确推荐的场景下使用;在库/生产代码中会降低可读性与可维护性。
典型用法与等价示例
-
直接导入
1
2
3import math
# 开平方
print(math.sqrt(4)) # 2.0 -
选择性导入
1
2
3from math import sqrt, pi
print(sqrt(4), pi) # 2.0 3.141592653589793 -
别名导入(避免冲突、缩短名称)
1
2
3
4
5import numpy as np
from datetime import datetime as dt
print(dt.now())
print(np.pi) -
星号导入(谨慎使用)
1
2
3
4# 假设有模块m,其中有foo与Bar成员
from m import *
foo()
Bar()
3.5 模块搜索顺序
Python 导入模块时,按以下顺序查找:
- 当前执行脚本所在目录(优先级最高)
sys.path列表中的目录(环境变量PYTHONPATH配置)- Python 标准库目录
- 第三方库安装目录(如
site-packages)
1 | import sys |
3.6 __all__控制导出
__all__是模块级列表,控制模块组件导出,用于指定from...import *时可导入的成员,仅对该导入方式有效。
修改 my_add.py,添加__all__:
1 | __all__ = ["num", "add"] # 仅允许导入num和add |
导入测试:
1 | from my_add import * |
3.7 __name__属性
``name`是 Python 模块的内置属性,是模块身份标识,用于标识模块运行状态:
- 文件直接运行时,
__name__值为 “main”; - 文件作为模块导入时,
__name__值为模块名(不含.py 后缀)。
实际应用场景
定义被导入使用的模块
1 | # 模块A:module_a.py |
定义模块使用者
1 | # 模块B:module_b.py |
默认模块名称会在被导入时改名
4 dir()函数与模块探索
dir()内置函数用于列出对象的属性和方法,或当前作用域中的名称,返回字符串列表。
dir()是探索模块功能的重要工具:
4.1 查看模块成员
1 | import math_tools |
4.2 查看对象属性
1 | from math_tools import add |
4.3 无参数使用与域归纳总结
无参数时,查看当前作用域的所有名称
1 | import math_tools |
打印结果解释:
- 模块级特殊属性
__name__:当前模块的名称,对于主程序通常是’main’
__file__:当前模块的文件路径
__doc__:模块的文档字符串(docstring)
__package__:模块所属的包名
__cached__:模块编译后的缓存文件路径(.pyc文件) - 模块加载相关
__loader__:负责加载此模块的对象
__spec__:模块的规格说明对象,包含模块的元数据
__builtins__:包含所有内置函数和异常的模块(如print、len等) - 其他属性
__annotations__:存储模块级别变量的类型注解
math_tools:导入的自定义模块
test_func:用户定义的函数
5 包(工程化组织)
包是 Python 中用于组织多个关联模块的目录结构,是模块的命名空间指定,核心特征是:
- 本质是包含
__init__.py文件的文件夹,__init__.py可为空,也可执行包初始化或设置__all__ - 用于将多个功能相关的模块归类管理
- 支持多层嵌套(包内可包含子包)
- 通过
包名.模块名的层级结构访问成员
5.1 包的典型结构
以一个数据处理工具包data_process为例:
1 | data_process/ # 顶级包 |
5.2 __init__.py的作用
__init__.py的实际使用场景并不多,几乎不使用,通常为空,或构建工具默认创建,这里简单了解
- 标识该目录为 Python 包
- 包初始化时执行的代码(如初始化配置、导入子模块)
- 定义
__all__控制from...import *导入的子模块 - 暴露包的公共接口(简化外部导入)
举例:
对应如下包结构的 __init__.py 包初始化文件,包含导入语句和包元数据
mypackage/
├── __init__.py
├── module1.py
└── module2.py
1 | """ |
6 创建包
基本步骤提示:
- 创建包文件夹
- 在包文件夹下创建
__init__.py文件- 添加模块文件(
xx.py、yy.py等)- 按需创建子包
在 PyCharm 中创建形状工具包 graphic,含__init__.py空文件即可、circle.py、rectangle.py 文件
结构如下:
1 | graphic/ #形状工具包 |
圆形模块circle.py 代码:
1 | """circle.py:圆形相关功能""" |
矩形模块rectangle.py 代码:
1 | """rectangle.py:矩形相关功能""" |
7 导入包
7.1 导入包内模块一(包名.模块名)
从包中导入模块,通过 “包名.模块名.成员名” 访问。
-
语法:
import 包名.模块名 [as 别名] -
案例:
1 | import graphic.circle |
7.2 导入包内的模块二(from包名import模块名)
从包中导入模块,通过 “模块名.成员名” 访问。
- 语法:
from 包名 import 模块名 [as 别名] - 案例:
1 | from graphic import circle |
7.3 导入包内模块的成员
直接导入包中模块的成员,直接通过成员名访问。
- 语法:
from 包名.模块名 import 成员名 [as 别名] - 案例:
1 | from graphic.circle import area |
7.4 包的全部导入
需在包的__init__.py中设置__all__,指定允许导入的模块。
__init__.py 文件修改:
1 | __all__ = ["circle"] # 仅允许导入circle模块 |
使用from xx import *的方式全部导入
1 | from graphic import * |
7.5 另一个完成案例
7.5.1 手动创建包(以data_process为例)
- 创建文件夹
data_process - 在该文件夹下创建
__init__.py文件 - 添加模块文件(
io_tools.py、clean_tools.py等) - 按需创建子包(如
utils文件夹及内部文件)
7.5.2 包内模块实现示例
io_tools.py(文件读写功能)
1 | """数据输入输出模块""" |
clean_tools.py(数据清洗功能)
1 | """数据清洗模块""" |
__init__.py(包初始化)
1 | """数据处理工具包""" |
7.5.3 导入包(多种方式)
7.5.3.1 导入包内模块
1 | # 方式1:导入包内模块,通过"包.模块.成员"访问 |
7.5.3.2 直接导入包的公共接口
借助__init__.py的配置,可直接导入包暴露的成员:
1 | # 直接导入包的公共函数(无需层级访问) |
7.5.3.3 导入子包成员
1 | # 导入子包的模块 |
7.5.3.4 全部导入包
1 | # 导入包的所有公共子模块(由__all__指定) |
8 常用标准库(包)
Python 标准库是内置的功能集合,无需安装即可使用,以下是高频使用场景及示例:
| 库名 | 核心功能 | 实战示例 |
|---|---|---|
os |
操作系统接口(文件 / 目录操作) | 遍历目录、创建文件夹 |
sys |
系统参数与函数 | 命令行参数、退出程序 |
datetime |
日期时间处理 | 时间格式化、日期计算 |
math |
数学运算 | 三角函数、对数计算 |
random |
随机数生成 | 随机抽样、打乱列表 |
re |
正则表达式 | 文本匹配、提取、替换 |
json |
JSON 数据处理 | 序列化、反序列化 |
collections |
高级容器 | 有序字典、计数器 |
更多的包总汇
| 名称 | 说明 |
|---|---|
| os | 操作系统接口(文件操作、路径处理等) |
| sys | 系统相关参数和函数(命令行参数、系统路径等) |
| time | 时间访问和转换 |
| datetime | 日期和时间处理类 |
| math | 数学函数(三角函数、对数等) |
| random | 生成伪随机数 |
| re | 正则表达式匹配 |
| json | JSON 数据编码与解码 |
| collections | 专门化容器(有序字典、计数器等) |
| functools | 高阶函数和可调用对象操作 |
| hashlib | 安全哈希与消息摘要 |
| urllib | URL 处理(请求发送、解析等) |
| smtplib | SMTP 协议客户端(邮件发送) |
| zlib/gzip/bz2 | 数据压缩与解压 |
| multiprocessing/threading | 进程与线程管理 |
| copy | 深浅拷贝操作 |
| socket | 网络编程接口 |
| shutil | 高级文件操作(拷贝、删除等) |
| glob | 路径名模式匹配 |
更多标准库可参考Python 官方文档。
常用库的使用
1. os库:目录遍历与文件操作
1 | import os |
2. datetime库:时间处理
1 | from datetime import datetime, timedelta |
3. json库:数据序列化
1 | import json |
9 第三方库管理
第三方库是社区开发的扩展功能包(如requests、pandas),需通过包管理工具安装。
9.1 pip 命令方式
pip 是 Python 包管理工具,支持查找、下载、安装、卸载第三方包,默认源为 PyPI,可指定国内源提速。
国内源地址:
pip 常用命令:
1 | # 升级pip --upgrade代表最新版本 |
安装 requests 包示例:
1 | # 安装 |
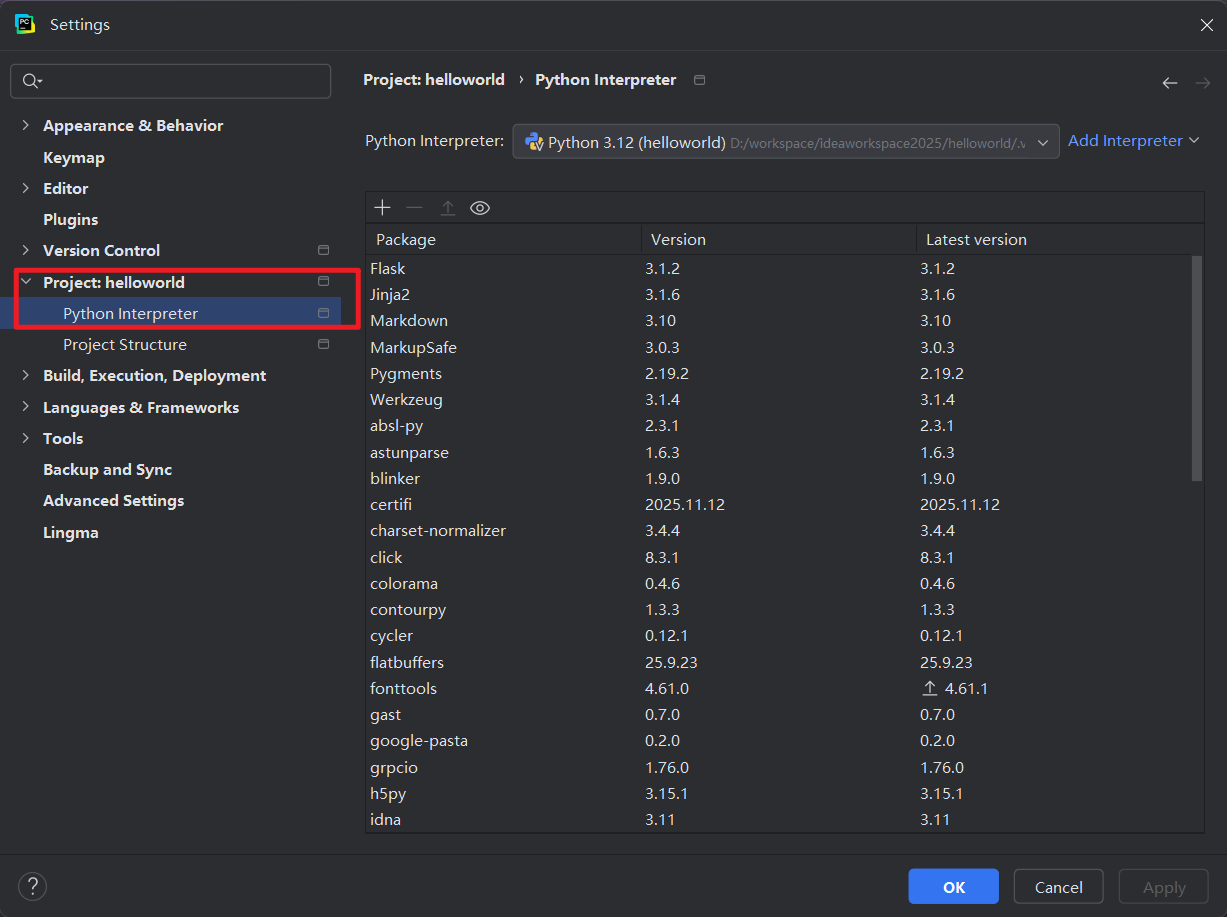
9.2 PyCharm 中管理第三方库
-
Settings中找到Python Interpreter(不同IDE版本设置位置不同),可以查看到目前安装的第三方包
-
点击 “+” 号,搜索要安装的包(如 requests);
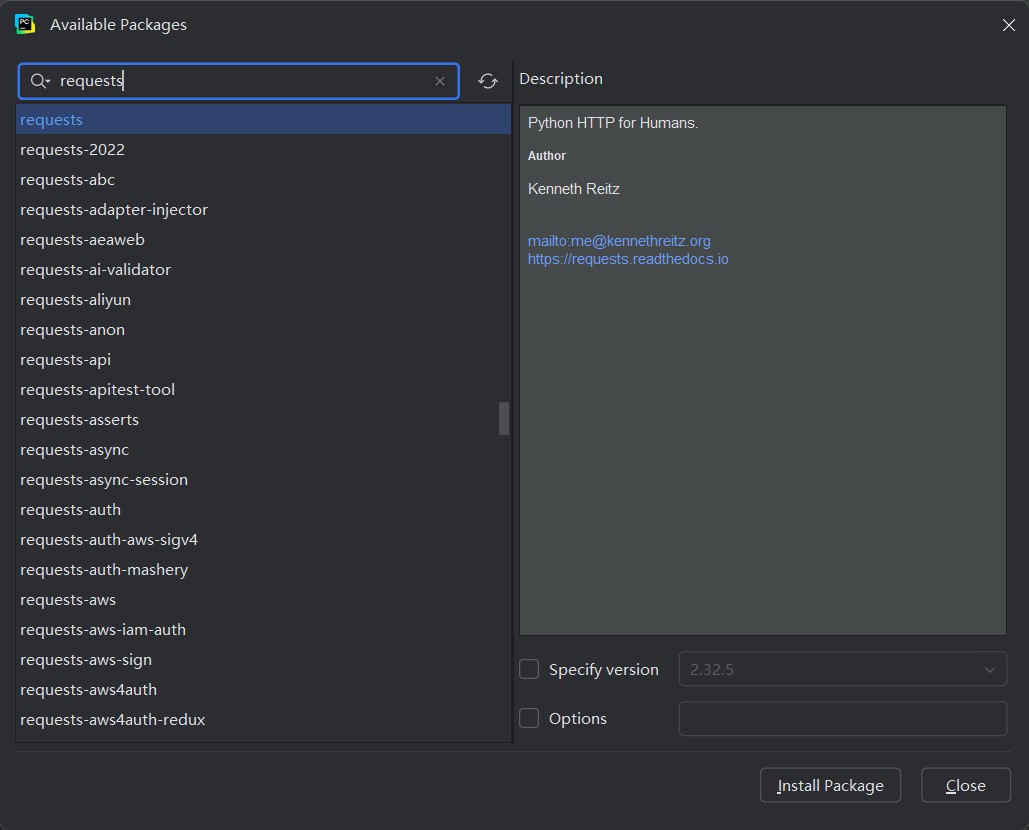
-
点击 “Install Package” 完成安装。
说明:PyCharm 安装的包会存放在当前项目的虚拟环境中(如D:\dev\workspace\工程名称\.venv\Lib\site-packages)。
9.3 requirements.txt文件管理
参见py概述.md#3.2.2 一些常规的PyCharm设置
9.4 虚拟环境(隔离项目依赖)
不同项目可能依赖不同版本的库,使用虚拟环境可避免冲突:
1 | # 创建虚拟环境(venv为环境名称) |
以上动作在pycharm创建项目时均会默认生成虚拟环境,所以无需手动,激活虚拟环境时,前边会有(.venv)提示
如果使用其他编辑工具打开,如命令行、cursor等集成化弱的IDE,则需要手动打开虚拟化搭建环境

10 打包自定义库(发布与分享)
将自己的模块 / 包打包为可安装的库,方便在多个项目中使用或分享给他人。
10.1 打包准备
安装打包工具:pip install setuptools wheel
- setuptools 库作用(本案例使用)
包构建工具:用于创建和管理Python包的分发版本
依赖管理:处理包之间的依赖关系声明和解析
入口点定义:允许定义命令行脚本和插件入口
元数据管理:管理包的版本、作者、许可证等信息 - wheel 库作用
现代分发格式:提供 .whl 格式的预编译包分发机制
快速安装:相比源码分发,wheel包安装速度更快
跨平台兼容:支持纯Python包和平台特定的二进制包
标准化格式:遵循PEP 427标准的分发格式
1 | #这里使用setuptools |
项目结构整理
1 | helloworld/ # 项目根目录 |
10.2 编写setup.py
与 graphic 包同级创建setup.py文件
1 | from setuptools import setup |
10.3 打包
1 | # 生成构建文件 |
构建及打包后的文件结构:其中graphic-1.0.tar.gz就是可以被安装的资源库了
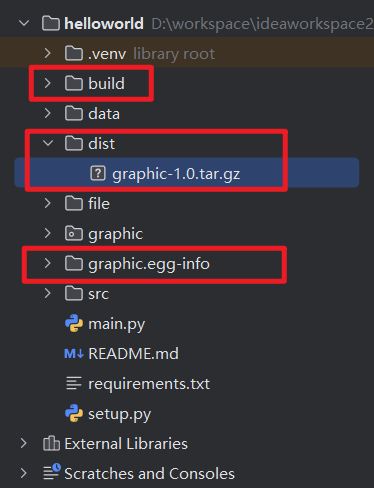
10.4 安装
- 命令安装
安装自定义包:
1 | # 通过pip安装 |
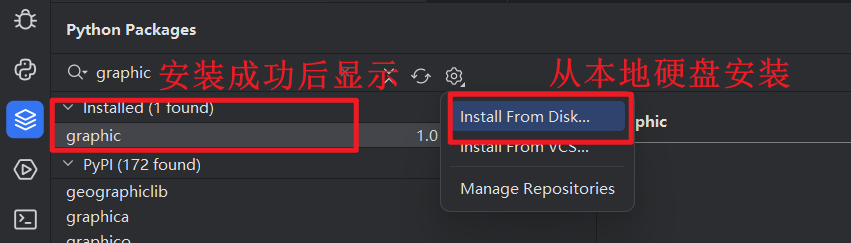
安装成功:
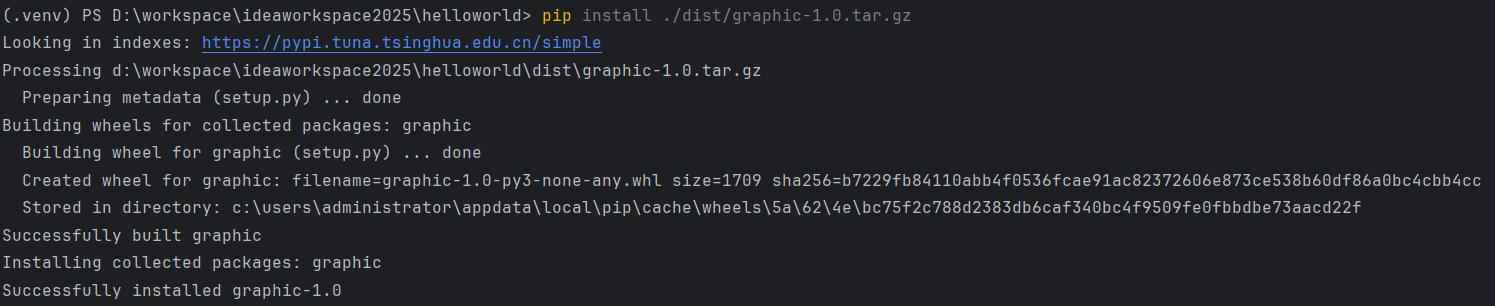
- PyCharm 中安装: