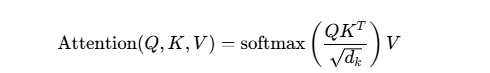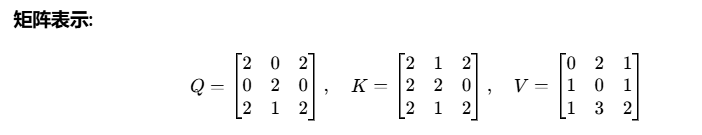进程与线程
程序 (Program):存放在磁盘上的静态指令和数据的集合 ,是“死”的、尚未运行的代码。
进程 (Process):程序的一次执行实例 。操作系统为其分配独立的内存和资源,是系统进行资源分配和调度的基本单位。
线程 (Thread):进程内部的一条执行流 ,是 CPU 调度的最小单位。同一进程的多个线程共享其资源,并发执行不同任务
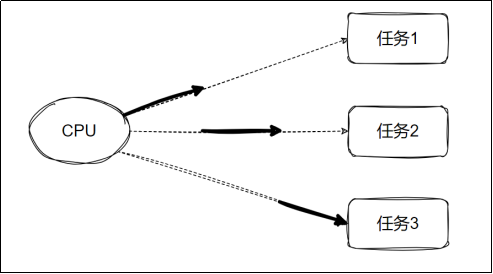
进程与线程均可以处理一个任务
1 核心概念:并发与并行
在多任务处理中,并发和并行是两个易混淆但核心的概念,直接决定程序的执行效率和资源利用方式:
1.1 并发(Concurrency)指软件/逻辑层面 的任务管理
定义 :单个 CPU 核心交替处理多个任务,通过快速切换营造 “同时执行” 的假象。
本质 :任务轮流占用 CPU 资源,同一时刻只有一个任务在执行。
适用场景 :I/O 密集型任务(如文件读写、网络请求),任务大部分时间在等待外部资源响应。
示例 :一个服务员同时接待多个顾客,轮流为每个顾客点单、上菜。
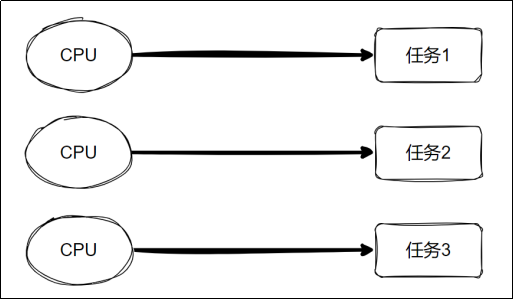
1.2 并行(Parallelism)指硬件层面 的真实同时执行
定义 :多个 CPU 核心同时处理多个任务,每个任务独占一个核心,真正实现 “同时执行”。
本质 :任务并行占用不同 CPU 资源,同一时间多个任务同步推进。
适用场景 :CPU 密集型任务(如数据计算、图像处理),任务主要消耗 CPU 运算资源。
示例 :多个服务员同时接待不同顾客,各自独立完成服务流程。
1.3 关键区别对比
特性
并发
并行
CPU 核心需求
单个即可
多个核心
执行方式
任务交替执行
任务同时执行
资源消耗
低(主要消耗切换开销)
高(消耗多核心资源)
适用任务类型
I/O 密集型(等待时间长)
CPU 密集型(运算时间长)
典型场景
多用户网络服务、文件批量处理
大数据计算、3D 渲染
2 多进程:独立资源的并行执行
2.1 进程核心概念
程序与进程是静态与动态的关系
进程是操作系统资源分配的基本单位 ,每个进程拥有独立的内存空间、文件描述符等资源。
进程间相互隔离,一个进程崩溃不会影响其他进程(保护模式下)。
进程创建和切换开销较大(需分配资源、保存上下文),但可充分利用多 CPU 核心。
2.2 进程创建
multiprocessing 是 Python 跨平台的多进程模块,Process 类是创建进程的核心。
核心参数与方法
1 multiprocessing.Process(group=None , target=None , name=None , args=(), kwargs={}, *, daemon=None )
参数 / 方法
说明
target进程要执行的目标函数
args目标函数的位置参数(元组形式)
kwargs目标函数的关键字参数(字典形式)
name进程名称(用于调试)
daemon是否为守护进程(True 时主进程退出则子进程强制终止)
start()启动进程(调用目标函数)
join([timeout])阻塞主进程,等待子进程结束(可选超时时间)
terminate()强制终止子进程
is_alive()检查进程是否正在运行
run()
默认调用传入 target 的对象,如果子类化了 Process ,可以重写此方法来自定义行为
pid获取进程 ID
group
无意义,用于与threading.Thread兼容,历史遗留问题,常设None
terminate()/kill()
强制结束进程
os.getpid()/getppid()
获取当前进程编号/当前进程的父进程编号
父进程:开启进程的进程,如main进程(即运行 if name == “main ” 块的进程)
基础用法(文件读写并发示例)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import timeimport multiprocessingdef write_file (): with open ("test.txt" , "a" , encoding="utf-8" ) as f: count = 0 while count < 5 : f.write(f"写入内容:{count} \n" ) f.flush() print (f"写进程:完成第 {count} 次写入" ) count += 1 time.sleep(0.5 ) def read_file (): with open ("test.txt" , "r" , encoding="utf-8" ) as f: time.sleep(0.2 ) while True : line = f.readline() if line: print (f"读进程:读到内容 -> {line.strip()} " ) else : if multiprocessing.active_children(): time.sleep(0.1 ) continue break if __name__ == "__main__" : pw = multiprocessing.Process(target=write_file, name="写进程" ) pr = multiprocessing.Process(target=read_file, name="读进程" ) pw.start() pr.start() pw.join() pr.join() print ("所有进程执行完毕" )
Unix/Linux :使用 fork() 复制当前进程,子进程从 fork 之后的位置继续执行;模块顶层代码不会重复执行,因此即便在顶层创建进程通常也不会触发递归问题。Windows :没有 fork ,采用“重新导入模块 + spawn 新解释器 ”的方式;子进程会从头执行模块代码,若顶层存在创建进程语句,就会重复启动,导致崩溃或无限递归。
2.3 自定义进程类
通过继承 Process 类,可更灵活地封装进程逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import osimport multiprocessingclass Worker (multiprocessing.Process): def __init__ (self, task_id ): super ().__init__() self .task_id = task_id def run (self ): print (f"进程 {self.task_id} 启动 | 进程 ID: {os.getpid()} | 父进程 ID: {os.getppid()} " ) time.sleep(1 ) print (f"进程 {self.task_id} 执行完毕" ) if __name__ == "__main__" : processes = [Worker(i) for i in range (3 )] for p in processes: p.start() for p in processes: p.join() print ("运行结束..." )
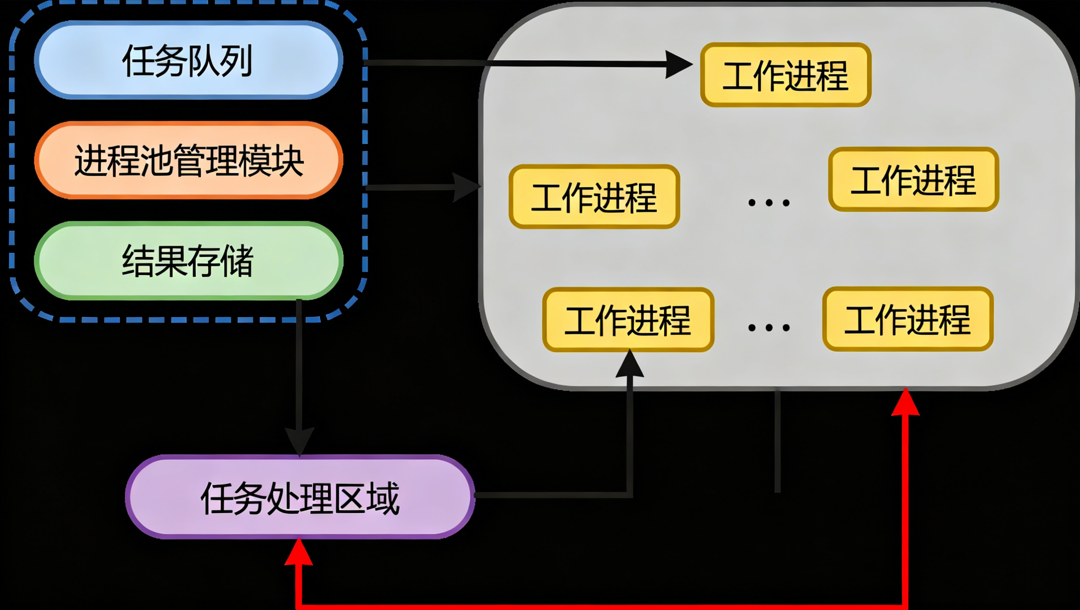
2.4 进程池:高效管理多进程
当需要创建大量子进程时,通常使用,Pool 进程池管理进程
为什么要使用进程池
降低创建与销毁开销 :进程的启动、退出、地址空间与资源初始化代价高;进程池通过预先创建固定数量的工作进程 并复用它们,显著减少频繁启停带来的系统开销。对于大量短任务 尤为关键,可避免“启动成本 > 计算成本”的倒挂现象
复用工作进程 :任务完成后不退出,继续从池的任务队列取活干,减少重复初始化与销毁的系统调用与内存分配。
内置限流与排队 :当池满时,新任务在队列中等待;有进程空闲再分配执行,避免“进程海”拖垮系统。
高层 API 简化开发 :通过 multiprocessing.Pool 的 map/apply/apply_async 或 concurrent.futures.ProcessPoolExecutor 的 submit/map/shutdown ,可便捷地提交任务、收集结果、管理生命周期,减少样板代码与错误。
结果收集与回调 :支持异步提交 + 回调 或批量 map ,便于在主进程中统一处理返回值、错误与汇总统计
进程池核心方法
1 multiprocessing.Pool([processes[,initializer[,initargs[,maxtasksperchild[,context]]]]])
processes :并发工作进程数;为 None 时默认使用 os.cpu_count() 。用于限制同时运行的进程数量,避免系统过载。
initializer :每个工作进程启动前调用的初始化可调用对象;为 None 表示不做初始化。适合做一次性资源准备(如日志配置、数据库连接池等)。
initargs :传递给 initializer 的参数元组。
maxtasksperchild :每个工作进程在退出并被替换前可完成的任务数;为 None 表示工作进程会一直存活到进程池关闭。用于定期回收资源、降低长期运行导致的资源泄漏风险。
context :用于指定进程启动上下文(如 spawn/fork/forkserver );一般使用默认即可,特殊场景(如与 CUDA 配合)可显式指定。
方法
说明
apply(func, args)同步执行任务,阻塞主进程直到任务完成
apply_async(func, args)异步执行任务,返回 AsyncResult 对象(通过 get() 获取结果)
map(func, iterable)批量异步执行任务,接收可迭代对象,返回结果列表
close()关闭进程池,不接收新任务((不会影响已经提交的任务))
terminate()立即终止所有进程(不管任务是否完成)
join()等待所有任务完成(必须在 close() 或 terminate() 后调用)
基础用法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import osimport timeimport multiprocessingdef func (): for i in range (10 ): print (os.getpid(), i) time.sleep(0.5 ) if __name__ == "__main__" : process_num = 5 pool = multiprocessing.Pool(process_num) for p in range (process_num): pool.apply_async(func) pool.close() pool.join() print ("end" )
批量提交任务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import osimport timeimport multiprocessingdef calculate (num ): print (f"进程 {os.getpid()} 处理任务:{num} " ) time.sleep(0.5 ) return num * num if __name__ == "__main__" : start_time = time.time() process_num = 4 pool = multiprocessing.Pool(process_num) results = pool.map (calculate, range (10 )) pool.close() pool.join() print (f"任务结果:{results} " ) print (f"总耗时:{time.time() - start_time:.2 f} 秒" )
2.5 进程间通信(IPC(Inter-Process Communication ))
进程间内存独立,无法直接共享变量,需通过专门的通信机制.
如以下案例:子进程向传入的列表中添加元素,最终发现主进程与子进程之间的列表结果不同
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import osimport multiprocessingdef func (list1 ): for i in range (10 ): list1.append(i) print (os.getpid(), list1) if __name__ == "__main__" : list1 = [] p1 = multiprocessing.Process(target=func, args=(list1,)) p2 = multiprocessing.Process(target=func, args=(list1,)) p1.start() p2.start() p1.join() p2.join() print (os.getpid(), list1)
1. 队列通信(multiprocessing.Queue)
适用于生产者 - 消费者模型,安全且跨平台:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import timeimport randomimport multiprocessingdef producer (queue ): while True : num = random.randint(1 , 100 ) queue.put(num) print (f"生产者放入:{num} " ) time.sleep(random.random()) def consumer (queue ): while True : num = queue.get() print (f"消费者处理:{num} -> 平方:{num*num} " ) time.sleep(0.3 ) if __name__ == "__main__" : queue = multiprocessing.Queue(maxsize=5 ) p1 = multiprocessing.Process(target=producer, args=(queue,), daemon=True ) p2 = multiprocessing.Process(target=consumer, args=(queue,), daemon=True ) p1.start() p2.start() time.sleep(5 ) print ("主进程结束" )
2. 管道通信(multiprocessing.Pipe)
适用于两个进程间双向通信,速度比队列快:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import multiprocessingdef send_data (pipe ): pipe.send("Hello from 进程 A" ) print (f"进程 A 发送:Hello from 进程 A" ) print (f"进程 A 接收:{pipe.recv()} " ) def recv_data (pipe ): print (f"进程 B 接收:{pipe.recv()} " ) pipe.send("Hello from 进程 B" ) print (f"进程 B 发送:Hello from 进程 B" ) if __name__ == "__main__" : conn1, conn2 = multiprocessing.Pipe() p1 = multiprocessing.Process(target=send_data, args=(conn1,)) p2 = multiprocessing.Process(target=recv_data, args=(conn2,)) p1.start() p2.start() p1.join() p2.join()
3. 共享内存(multiprocessing.Value/Array)
适用于高频数据共享,需手动加锁保证线程安全:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import multiprocessingdef add_num (value, lock ): for _ in range (10 ): with lock: value.value += 1 if __name__ == "__main__" : shared_num = multiprocessing.Value("i" , 0 ) lock = multiprocessing.Lock() p1 = multiprocessing.Process(target=add_num, args=(shared_num, lock)) p2 = multiprocessing.Process(target=add_num, args=(shared_num, lock)) p1.start() p2.start() p1.join() p2.join() print (f"最终结果:{shared_num.value} " )
3 多线程:共享资源的并发执行
3.1 线程的核心特性
线程是操作系统任务调度的最小单位
一个进程至少有一个线程,也可以运行多个线程
多个线程之间可共享数据
线程间相互依赖,一个线程崩溃可能导致整个进程终止(基本不会出现,线程本身也是隔离的)
多线程是指在同一进程中同时执行多个任务
3.2 线程创建:threading.Thread
threading 是 Python 标准库的多线程模块,用法与 multiprocessing.Process 类似
1 threading.Thread(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
基础用法(交替打印示例)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import threadingimport timedef print_num (start,end ): for i in range (start,end+1 ): print (f"{threading.current_thread().name} 号线程打印:{i} " ) time.sleep(0.1 ) if __name__ == '__main__' : t1 = threading.Thread(target=print_num,args=(1 ,5 ),name="小美" ) t2 = threading.Thread(target=print_num,args=(1 ,10 ),name="小帅" ) t1.start() t2.start() t1.join() t2.join() print ("主线程结束" )
自定义线程类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import threadingclass MyThread (threading.Thread): def __init__ (self, task_id ): super ().__init__() self .task_id = task_id def run (self ): print (f"线程 {self.task_id} 启动 | 线程 ID: {self.ident} " ) time.sleep(1 ) print (f"线程 {self.task_id} 执行完毕" ) if __name__ == "__main__" : threads = [MyThread(i) for i in range (3 )] for t in threads: t.start() for t in threads: t.join()
3.3 线程池:concurrent.futures.ThreadPoolExecutor
ThreadPoolExecutor ,线程池管理类
1 concurrent.futures.ThreadPoolExecutor(max_workers=None , thread_name_prefix="" , initializer=None , initargs=())
基础用法(批量网络请求示例)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import threadingimport timefrom concurrent.futures.thread import ThreadPoolExecutorimport requestsdef fetch_url (url ): print (f"{threading.current_thread().name} 正在请求的url为:{url} " ) try : start_time = time.time() response = requests.get(url, timeout=3 ) return f"{threading.current_thread().name} 访问的{url} 返回的状态码:{response.status_code} " except Exception as e: return f"{threading.current_thread().name} 访问的{url} 发生异常:{e} " finally : end_time = time.time() print (f"{threading.current_thread().name} 访问{url} ,用时{end_time - start_time} 线程结束" ) if __name__ == '__main__' : url_list = [ "https://www.baidu.com" , "https://www.google.com" , "https://www.github.com" , "https://www.python.org" ] start_time = time.time() with ThreadPoolExecutor(max_workers=3 ) as executor: results = executor.map (fetch_url, url_list) print ( results) print ( type (results)) results_list = list (results) for result in results_list: print ( result) end_time = time.time() print (f"访问{url_list} 地址,共耗时:{end_time - start_time} 秒" )
3.4 线程安全:互斥锁与条件变量
线程共享资源,当多个线程修改同一资源时,会出现数据竞争 (数据不一致),需通过同步机制保证线程安全
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 """ 线程安全出现前提: 1.多线程参与 2.多线程共享数据 3.多线程修改数据 出现线程安全最重要的原因:原子性问题 原子性:不可拆分的一个整体性质。每个进程在执行任务时,某些步骤是不能分割执行的,应该将所有该动作执行的代码看作一个原子性操作,操作过程中,不能让CPU执行操作同一个数据的代码 所以:多线程操作共享数据时,应该保持原子性操作不被插入打断,否则会出现线程安全问题 """ import threadingfrom time import sleepdef add_num (value ) : for i in range (10 ) : current_value = value['value' ] sleep(0.001 ) new_value = current_value + 1 sleep(0.001 ) value['value' ] = new_value sleep(0.001 ) print (f"{threading.current_thread().name} 线程执行+1,此次结果为:{value['value' ]} " ) if __name__ == '__main__' : shared_num = {"value" : 0 } t1 = threading.Thread(target=add_num, args=(shared_num,),name="小美" ) t2 = threading.Thread(target=add_num, args=(shared_num,),name="小帅" ) t1.start() t2.start() t1.join() t2.join() expected = 20 actual = shared_num["value" ] print (f"预期结果:{expected} ,实际结果:{actual} " ) if expected == actual: print ("没有出现数据安全问题" ) else : print ("出现了数据安全问题" )
出现线程安全最重要的原因:原子性问题
原子性:不可拆分的一个整体性质。每个进程在执行任务时,某些步骤是不能分割执行的,应该将所有该动作执行的代码看作一个原子性操作,操作过程中,不能让CPU执行操作同一个数据的代码
所以:多线程操作共享数据时,应该保持原子性操作不被插入打断,否则会出现线程安全问题
1. 互斥锁(threading.Lock)
某个线程要更改共享数据时,先将其锁定,此时其他线程不能更改。直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性
使用互斥锁达到了线程安全:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 """ 线程:threading.Lock() 多个线程操作同一个数据,需要使用同一个锁对象 """ import threadingfrom time import sleepdef add_num (value,lock ) : for i in range (1000 ) : lock.acquire() try : current_value = value['value' ] sleep(0.001 ) new_value = current_value + 1 sleep(0.001 ) value['value' ] = new_value sleep(0.001 ) print (f"{threading.current_thread().name} 线程执行+1,此次结果为:{value['value' ]} " ) finally : lock.release() sleep(0.0001 ) if __name__ == '__main__' : shared_num = {"value" : 0 } lock = threading.Lock() t1 = threading.Thread(target=add_num, args=(shared_num,lock),name="小美" ) t2 = threading.Thread(target=add_num, args=(shared_num,lock),name="小帅" ) t1.start() t2.start() t1.join() t2.join() expected = 2000 actual = shared_num["value" ] print (f"预期结果:{expected} ,实际结果:{actual} " ) if expected == actual: print ("没有出现数据安全问题" ) else : print ("出现了数据安全问题" )
2. 条件变量(threading.Condition)
用于线程间通信(如生产者 - 消费者模型的同步):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 import randomimport threadingfrom time import sleepclass Queue : def __init__ (self, max_size ): self .max_size = max_size self .queue = [] self .cond = threading.Condition() def put (self, item ): with self .cond: while len (self .queue) >= self .max_size: print ("队列已满,不再生产,生产等待" ) self .cond.wait() self .queue.append( item) print (f"生产者: 生产了一个数据 -> {item} | 队列全部数据:{self.queue} " ) self .cond.notify() def get (self ): with self .cond: while len (self .queue) <= 0 : print ("队列已空,不再消费,消费等待" ) self .cond.wait() item = self .queue.pop(0 ) print (f"消费者: 消费了一个数据 -> {item} | 队列全部数据:{self.queue} " ) self .cond.notify() return item def producer (queue ): for i in range (5 ): queue.put(i) sleep(random.random()) def consumer (queue ): for i in range (5 ): queue.get() sleep(random.random()) if __name__ == '__main__' : queue = Queue(max_size=2 ) t_p = threading.Thread(target=producer, args=(queue,)) t_c = threading.Thread(target=consumer, args=(queue,)) t_p.start() t_c.start() t_p.join() t_c.join() print ("主线程结束" )
4 进程与线程使用对比
4.1 GIL:Python 线程的 “隐形限制”
GIL(Global Interpreter Lock,全局解释器锁)是 CPython 解释器的特性,同一时刻只允许一个线程保持 Python 解释器的控制权,这意味着在任何时间点都只能有一个线程处于执行状态 ,即使在多 CPU 核心上,多线程也无法实现真正的并行。
4.2 核心对比
特性
进程
线程
资源占用
高(独立内存、文件描述符)
低(共享进程资源)
创建 / 切换开销
大
小
通信复杂度
高(需 IPC 机制)
低(直接共享变量)
稳定性
高(进程隔离)
低(线程崩溃影响进程)
GIL 影响
无(多进程并行)
有(多线程无法并行 CPU 任务)
4.3 选择原则
CPU/GPU 密集型任务 (如计算、加密、图像处理):选多进程(充分利用多核心)。I/O 密集型任务 (如文件读写、网络请求、数据库操作):选多线程(低开销,高并发)。任务数量多且轻量 :选线程池(减少线程创建开销)。任务独立性强、需隔离 :选多进程(避免一个任务崩溃影响整体)。
4.4 多进程安全问题与多线程安全问题的关系
相似性
主要区别
内存模型
同步机制
资源开销
错误传播
安全保障
4.5 py脚本模拟网络请求的多任务选择
推荐方案:多线程
原因分析
适用场景
实现建议
注意事项
4.6 AI模型数据处理的多任务选择
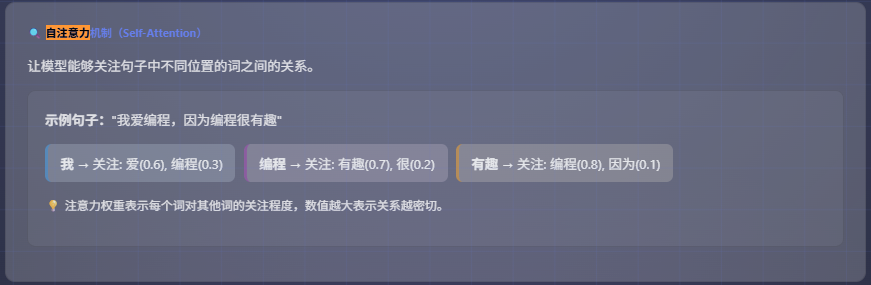
例如ai中Transformer架构(一种革命性的深度学习神经网络架构)提供的自注意力机制 ,会将一句话分词并转换为向量,然后通过一次矩阵运算为整句话生成 Q、K、V 三个矩阵。这些计算是高度相关的,它们共同构成了一个完整的自注意力层 ,在实际的 PyTorch/TensorFlow(用于搭建和训练深度学习模型的开源框架) 实现中,虽然 Python 解释器受 GIL 限制,但底层的矩阵运算由 C++/CUDA 等库在 GPU/CPU 上并行执行。因此,在服务端部署时,通常采用多线程 来高效地调度这些并行计算任务(如处理多个请求或多头注意力),并共享模型参数和中间结果。
根据自注意力公式:
最终会将一句话生成Q/K/V矩阵(自注意力机制后续计算的基础),类似这样(每行代表一个分词):
Q (Query) :代表“查询者”,用于去“询问”其他词。
K (Key) & V (Value) :代表“被查询的内容”。每个词也都有自己的键值对 (k_i, v_i),供其他词的 Q来查询。
计算第 i个词的输出时,需要用到所有词 的 K和 V,但仅使用第 i个词 自己的 Q
LLM 对输入(比如一句话)在每一层 Transformer 中都会生成 Q、K、V 矩阵 ,并在该层用它们做自注意力计算,然后把结果传给下一层,形成多层堆叠
1. 数据局部性与共享状态
在计算第 i个词的注意力时,你需要访问所有其他词的信息(即整个句子的 K和 V矩阵)。
如果使用多进程 ,每个进程都有自己独立的内存空间。这意味着:
你需要将整个 K和 V矩阵复制 给每一个进程。
进程间通信(IPC)会有显著的开销。
如果使用多线程 ,所有线程都共享同一份 K和 V矩阵。当一个线程读取数据时,其他线程也可以直接读取,零拷贝,速度极快 。
2. 任务粒度与开销
要处理的任务数量等于句子长度(比如20个词)。这是一个非常轻量级的任务集合。
创建进程的开销非常大 (毫秒级),而创建线程的开销非常小 (微秒级)。为了处理20个词去创建20个进程,然后还要进行进程间通信,这在性能上是完全不可接受的。
3. 现代框架的实现方式
很多框架,底层会自动调用高度优化的库。
这些库本身就是多线程 的。它会自动利用你电脑的所有CPU核心或GPU核心来进行并行计算。
举个例子:
这就像一家餐厅(你的程序)接到一个订单(一个句子)。
多线程 :厨房里的几个厨师(线程)共享同一个冰箱(内存),一起协作完成一道菜(一个句子)的不同步骤。他们之间沟通顺畅,效率极高。多进程 :你为了切一根葱(一个词),专门开了一家新餐厅(进程),这家新餐厅还需要从老餐厅运过去所有的食材(数据拷贝)。
4.7 什么时候会考虑多进程?
虽然在这个具体任务上不适用,但多进程在AI领域有其不可替代的价值,主要体现在任务级别的并行 :
场景
原因
批量推理 你有1000个句子要处理。与其一个接一个地算,不如开4个进程,每个进程处理250个句子。它们各自独立,互不干扰,实现了批处理任务的并行。
服务高并发 一个Web API同时收到100个请求。为每个请求创建一个独立的进程(或使用进程池),可以避免某个请求的异常导致整个服务崩溃。
模型集成 你要同时使用BERT、RoBERTa、GPT等多个不同的模型做预测。每个模型可以在自己的进程中运行,避免相互阻塞。
继续上面的比喻:
多进程 :餐厅一下子来了100个订单。老板开了10个分店(进程),每个分店独立处理10个订单。这样总的处理速度就快了10倍。