
python高级语法
高级语法
1 浅拷贝与深拷贝
拷贝是 Python 中数据复用的核心手段,核心差异在于是否复制嵌套对象,直接决定数据独立性。理解拷贝机制能避免开发中因数据共享导致的意外修改问题。
1.1 核心概念与适用场景
| 拷贝类型 | 核心特点 | 内存机制 | 适用场景 |
|---|---|---|---|
| 直接赋值 | 仅传递引用,不产生新对象 | 多个变量指向同一内存地址 | 无需数据独立,共享原始数据(如只读配置) |
| 浅拷贝 | 拷贝父对象,嵌套子对象仍共享引用 | 顶层对象新地址,嵌套对象同地址 | 单层数据结构(如扁平列表),无需修改嵌套内容 |
| 深拷贝 | 完全拷贝父对象及所有子对象 | 顶层 + 嵌套对象均为新地址 | 嵌套数据结构(如列表套字典),需完全独立修改 |
1.2 浅拷贝实现方式
浅拷贝有 3 种常用实现方式,效果完全一致,可根据场景选择:
- 切片操作:
list2 = list1[:](仅适用于序列类型,如列表、元组) - 工厂函数:
list2 = list(list1)、set2 = set(set1)(支持序列和集合) copy模块:list2 = copy.copy(list1)(通用型,支持所有可拷贝对象)
1.3 浅拷贝实战案例(含嵌套数据)
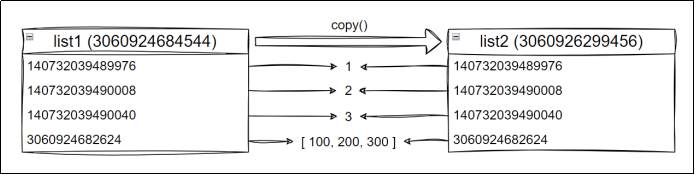
1 | import copy |
1.4 深拷贝实现与案例
深拷贝仅通过copy模块的deepcopy()实现,完全隔离所有层级数据:

1 | import copy |
1.5 特殊场景说明
-
不可变类型(int、str、tuple)的拷贝:无论浅拷贝还是深拷贝,都不会产生新对象(因不可变类型无法修改,复用内存更高效)
1
2
3
4
5import copy
a = (1, 2, 3) # 元组(不可变类型)
b = copy.copy(a)
c = copy.deepcopy(a)
print(id(a) == id(b) == id(c)) # 输出:True(均指向同一地址) -
元组嵌套可变对象:元组本身不可变,但嵌套的可变对象仍遵循拷贝规则
1
2
3
4
5import copy
t = (1, [2, 3])
t_copy = copy.copy(t)
t[1].append(4)
print(t_copy[1]) # 输出:[2, 3, 4](嵌套列表共享引用)
2 迭代器
迭代器是 Python 中遍历可迭代对象的核心机制,是可以记住遍历位置的对象,大幅提升内存效率,尤其适用于大数据量场景。
2.1 核心概念区分
| 概念 | 定义 | 判定方式 |
|---|---|---|
| 可迭代对象(Iterable) | 支持被iter()函数调用生成迭代器的对象 |
isinstance(obj, Iterable) |
| 迭代器(Iterator) | 实现__iter__()和__next__()方法的对象 |
isinstance(obj, Iterator) |
-
可迭代对象
-
可迭代对象(Iterable)指能被 for 循环遍历的对象,通常为实现了 iter() 方法,或实现了 getitem() 并支持从 0 开始的整数索引的对象
-
使用 isinstance(obj, collections.abc.Iterable) 进行类型判定
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32from collections.abc import Iterable
# 列表:list,内置可变序列类型,支持迭代
print(isinstance([], Iterable)) # True
# 元组:tuple,内置不可变序列类型,支持迭代
print(isinstance((), Iterable)) # True
# 集合:set,内置可变集合类型,支持迭代
print(isinstance(set(), Iterable)) # True
# 字典:dict,内置映射类型;默认迭代的是“键”
print(isinstance({}, Iterable)) # True
# 字符串:str,内置序列类型,按字符迭代
print(isinstance("100", Iterable)) # True
# 整数:int,内置数值类型,非可迭代对象
print(isinstance(100, Iterable)) # False
for element in [1, 2, 3]:
print(element)
for element in (1, 2, 3):
print(element)
for key in {"one": 1, "two": 2}:
print(key)
for char in "123":
print(char)
for line in open("test.txt"):
print(line, end="") -
内置可迭代类型总览
分类 代表类型 说明 容器类 list、tuple、str、set、dict、frozenset 常见内置容器,均可在 for 中遍历;dict 默认迭代键 序列与字节 range、bytes、bytearray、memoryview 序列或字节视图,支持索引/切片(memoryview 为内存视图) 文件对象 io.TextIOBase/io.BufferedIOBase(文本/二进制文件) 文件对象本身可逐行/逐块迭代 迭代器与生成器 iterator、generator、generator expression 迭代器遵循迭代协议;生成器是特殊的迭代器 高阶返回迭代器 enumerate、zip、map、filter、reversed 内置函数/类型,返回迭代器用于惰性组合、过滤、映射、反转 字典视图 dict_keys、dict_values、dict_items 视图对象,惰性反映字典变化,可迭代 其他常见 collections.deque、queue.Queue、itertools.chain/islice/… 标准库容器与工具,返回迭代器或自身可迭代
-
2.2 迭代器及其与可迭代对象关系
- 可迭代对象通过
iter()函数生成迭代器 - 迭代器通过
next()函数获取下一个元素,耗尽时抛出StopIteration异常 - 迭代器本身也是可迭代对象(
__iter__()返回自身)
1 | from collections.abc import Iterable, Iterator |
2.3 自定义迭代器(实战案例)
通过实现__iter__()和__next__()方法,创建自定义迭代器(如斐波那契数列生成器):
1 | class FibIterator: #0 1,1,2,3,5.... |
练习,定义反向列表遍历器,并使用
1 | class Reverse: |
2.4 迭代器的优势与应用场景
- 内存高效:无需一次性加载所有数据,按需生成(如处理 100 万条数据时仅占用少量内存)
- 支持无限序列:如无限斐波那契数列(通过迭代器可一直生成,不会内存溢出)
- 统一遍历接口:无论何种可迭代对象,都可通过
for循环统一遍历
3 生成器
生成器是迭代器的简化实现,通过yield关键字实现,语法更简洁,是 Python 中处理大数据量的首选工具。
3.1 生成器的核心特性
- 语法简洁:无需手动实现
__iter__()和__next__()方法 - 惰性计算:遇到
yield暂停,再次调用时从暂停处继续执行 - 状态保留:自动保留函数执行状态(如变量值、执行位置)
3.2 生成器的两种创建方式
1. 生成器表达式(简洁版)
语法:(表达式 for 变量 in 可迭代对象 if 条件)(类似列表推导式,将[]改为())
1 | # 生成1-10的平方(生成器表达式) |
2. 生成器函数
通过def定义,包含yield关键字的函数即为生成器函数,调用后返回生成器对象:
1 | def fibo(): # 斐波那契数列 |
如果我们要获取生成器中 return 的值,我们需要捕获 StopIteration异常:
1 | def fibo(n): # 斐波那契数列 |
3.3 生成器的高级用法
1. send()方法:向生成器发送数据
send()可在唤醒生成器的同时传递数据,实现双向通信:send()发送的数据作为yield表达式的结果
1 | def echo_generator(): |
2. close()方法:手动终止生成器
1 | gen = (x for x in range(10)) |
3.4 生成器实战:处理大数据文件
场景:读取 10GB 日志文件,统计包含 “error” 的行数(无需加载整个文件到内存)
1 | def error_log_counter(file_path): |
4 命名空间与作用域
命名空间和作用域决定了变量的访问规则,理解它们能避免变量命名冲突和访问异常。
4.1 命名空间(NameSpace)
命名空间是变量名到对象的映射字典,用于隔离不同上下文的变量,避免命名冲突。
三种命名空间
| 命名空间类型 | 创建时机 | 生命周期 | 访问方式 |
|---|---|---|---|
| 内置命名空间 | Python 解释器启动时 | 解释器退出时销毁 | 全局可访问(如print()、len()) |
| 全局命名空间 | 模块加载时 | 模块卸载时销毁 | 模块内全局访问 |
| 局部命名空间 | 函数调用时 | 函数执行结束后销毁 | 仅函数内部访问 |
命名空间查找顺序
当访问变量时,Python 按以下顺序查找:局部命名空间 → 外层嵌套命名空间 → 全局命名空间 → 内置命名空间,找不到则抛出NameError。
1 | # 全局作用域 |
4.2 作用域(Scope)
作用域是命名空间的可访问范围,分为四种:
- L(Local):局部作用域(函数内部)
- E(Enclosing):外层嵌套作用域(如闭包外层函数)
- G(Global):全局作用域(模块内部)
- B(Built-in):内置作用域(Python 内置)
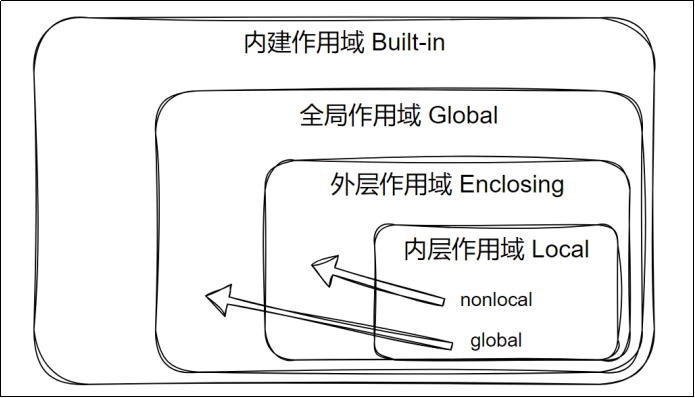
作用域修饰符
-
global:声明变量为全局变量,可在局部修改全局变量1
2
3
4
5
6
7
8count = 0 # 全局变量
def increment():
global count # 声明使用全局变量
count += 1
increment()
print(count) # 输出:1 -
nonlocal:声明变量为外层嵌套作用域变量(适用于闭包)1
2
3
4
5
6
7
8
9def outer():
x = 10 # 外层嵌套变量
def inner():
nonlocal x # 声明使用外层变量
x += 5
inner()
return x
print(outer()) # 输出:15
5 闭包
闭包是 Python 高级特性之一,允许函数嵌套中内层函数访问外层函数的变量,即使外层函数已执行完毕。核心价值是数据封装和状态保留。
5.1 闭包的构成条件
- 外层函数内定义内层函数
- 内层函数引用外层函数的变量(非全局变量)
- 外层函数返回内层函数对象
闭包理解案例:
1 | # 构建闭包 |
5.2 闭包实战案例
案例 1:计数器(状态保留)
1 | def counter(): |
案例 2:配置型函数(数据封装)
1 | def make_multiplier(factor): |
5.3 闭包的注意事项
-
闭包会保留外层变量的引用,可能导致内存占用(避免保留大对象)
-
外层变量若为可变类型(列表、字典),无需
nonlocal即可修改1
2
3
4
5
6
7
8
9
10def outer():
lst = []
def inner(item):
lst.append(item) # 可变类型无需nonlocal
return lst
return inner
add_item = outer()
print(add_item(1)) # 输出:[1]
print(add_item(2)) # 输出:[1, 2]
6 装饰器
装饰器是 Python 中动态增强函数 / 类功能的高级语法,基于闭包实现,核心优势是不修改原始代码即可扩展功能,符合 “开放 - 封闭” 原则。
思考:为什么装饰器基于闭包实现?
6.1 装饰器的核心语法
1 | # 装饰器函数(接收函数为参数,返回新函数) |
*args 参数
作用:接收任意数量的位置参数(positional arguments)
特点:将传入的位置参数收集为一个元组(tuple)
使用场景:当不确定函数会接收多少个位置参数时使用
**kwargs 参数
作用:接收任意数量的关键字参数(keyword arguments)
特点:将传入的关键字参数收集为一个字典(dictionary)
使用场景:当不确定函数会接收多少个关键字参数时使用语法糖:
语法糖是指编程语言中为了提高代码可读性和编写便利性而提供的简化语法,它并不增加语言的功能,只是让某些操作更容易表达。
6.2 常用装饰器实战
1. 计时装饰器(统计函数执行时间)
1 | import time |
2. 缓存装饰器(缓存函数返回结果)
1 | def cache_decorator(func): |
3. 带参数的装饰器
需要额外一层函数接收参数,实现装饰器的灵活配置:
案例1:
1 | from math import sqrt |
案例2:参数直接指定
1 | def log_decorator(prefix="INFO"): |
6.3 类装饰器
通过类的__call__()方法实现装饰器,支持更复杂的状态管理:
- 不带参数类装饰器
不带参数时,类的逻辑直接作为装饰器使用,init函数接收的是函数调用时传入的参数
两层结构:类初始化接收函数 → call 接收函数调用参数并执行得到结果,即call方法就是包装方法
1 | from math import sqrt |
- 带参数类装饰器
带参时,先init初始化创建装饰器实例,然后该实例的逻辑装饰函数
init方法的参数为装饰器参数
call方法参数为被装饰方法
call方法的内部闭包包装方法,参数为函数调用时的参数
需要三层结构:类初始化,创建对象 → call 接收函数 → 返回包装函数
1 | class RetryDecorator: |
6.4 装饰器其他
-
保留原始函数元信息:使用
functools.wraps避免装饰器掩盖原始函数信息1
2
3
4
5
6
7
8
9
10
11
12
13
14
15from functools import wraps
def decorator(func):
# 保留原始函数元信息
def wrapper(*args, **kwargs):
return func(*args, **kwargs)
return wrapper
def test():
"""测试函数"""
pass
print(test.__name__) # 输出:test(未用wraps则输出wrapper)
print(test.__doc__) # 输出:测试函数(未用wraps则输出None) -
多层装饰器:装饰器按从上到下的顺序执行
1
2
3
4
5
def func():
pass
# 等价于:func = decorator1(decorator2(func))




